
for и генераторы, require и assertflatMapScala является одним из основных языков программирования, который используется в Twitter. Большая часть нашей инфраструктуры написана на Scala и у нас есть несколько крупных библиотек, которые нами поддерживаются.
Scala не только очень эффективный, но и большой язык. Полученный нами опыт, научил нас быть очень осторожным при его использовании в своих приложениях в боевых условиях. Какие есть подводные камни? Какие особенности стоит использовать, а от каких отказаться? Когда мы можем использовать «чисто функциональный стиль», а когда его следует избегать? Другими словами: что мы ежедневно используем, чтобы быть более эффективными используя этот язык? Это руководство пытается передать наш опыт в коротких заметках, представляя их как набор лучших практик. Мы используем Scala для создания высококачественных сервисов, которые представляют собой распределенные системы - наше мнение возможно будет предвзято - но большинство советов здесь должны работать без проблем и при переносе на другие системы. Все эти советы не являются истиной в последней инстанции, и небольшое отклонение должно быть вполне приемлемым.
Scala предоставляет множество инструментов, которые позволяют кратко описывать свои действия. Если мы меньше будем набирать текста, значит меньше придется читать, а значит исходный код будет прочитан быстрее, поэтому краткость кода повышает его ясность. Однако краткость может быть оказаться и плохим помощником, который может оказать обратный эффект: вслед за правильностью, всегда нужно думать о читателе.
Немного, о Scala-программе. Вы не пишете код ни на Java, ни на Haskell, ни на Python; написание Scala-программы отличается от написания на любом из этих языков. Для того чтобы использовать язык эффективно, вы должны описать свои проблемы, в терминах этого языка. Вас никто не принуждает использовать программу, написанную на Java, в Scala, в большинстве случаев она будет уступать оригиналу.
Данный документ не введение в язык Scala, мы предполагаем, что читатель знаком с языком. Вот некоторые ресурсы для обучения языку Scala:
Данный набор статей - это живой документ, который будет меняться с учетом наших текущих “лучших практик”, но основные идеи вряд ли изменятся: писать код, который всегда будет легко читаем; писать универсальный код, но не в ущерб ясности; пользоваться простыми функциями языка, которые обладают большой мощью, но избегать эзотерических функций (особенно в системе типов). Прежде всего, всегда нужно находить компромиссы в том, что вы делаете. Сложность языка требуется в комплексных реализациях, потому что она порождает сложность: в рассуждениях, в семантике, во взаимодействия между особенностями системы, а также в понимании между вашими сотрудниками. Таким образом, трудность является производной от сложности - вы всегда должны убедиться, что ее полезность превышает ее стоимость.
И получайте удовольствие.
Специфические способы форматирования кода - пока они полезны - не имеют большого значения. По определению, стиль не может быть хорошим или плохим, почти все определяет личное предпочтение. Однако, последовательное применение одних и тех же правил форматирования будет почти всегда увеличивать удобочитаемость. Читатель, уже знакомый с данным стилем, не должен разбираться в еще одном наборе местных соглашений или расшифровать еще одну часть языковой грамматики.
Это имеет особое значение для Scala, поскольку у его грамматики высокий уровень вхождения. Один говорящий пример - вызов метода: Методы
могут быть вызваны с помощью “.”, либо с использованием пробела, либо без круглой скобки для не методов, не возвращающих значений, или для унарных методов, с круглой скобкой для этих же случаев, и так далее. Кроме того, различные стили вызова методов оставляют двусмысленность в его грамматике! Конечно, последовательное применение заранее определенного набора правил форматирования решит большую часть двусмысленности и для человека, и для машины.
Мы придерживаемся [Правила форматирования в языке Scala] (http://docs.scala-lang.org/style/) и дополнительно следующих правил.
При отступе используется 2 пробельных символа. Мы стараемся избегать строк, длиной более 100 символов. Мы используем одну пустую строку между методом, классом и определениями объекта.
i,j и k и тому подобные переменные в циклах Future.collect вместо Future.all.
ok, err или defn,а вот sfri используется не так часто.
val` для перегрузки зарезервированных имен.typ вместо `type`user.activate() вместо user.setActive()src.isDefined вместо src.definedgetsite.count вместо site.getCount object User {
def get(id: Int): Option[User]
}object User {
def getUser(id: Int): Option[User]
}User.getUser дает не больше информации, чем User.get.
import com.twitter.concurrent.{Broker, Offer}import com.twitter.concurrent._
scala.collection.immutable и/или scala.collection.mutableimmutable.Map")import com.twitter
import concurrentimport com.twitter.concurrentФигурные скобки используются для создания сложных выражений (они служат другим целям в “module language”), где значение соответствующего выражения является последним выражением в списке. Старайтесь не использовать скобки для простых выражений; пишите
def square(х: Int) = х*х
.LP, вместо
def square(х: Int) = {
х * х
}
.LP, хотя это может быть привлекательным, чтобы отличить тело метода синтаксически. Первый вариант имеет меньший беспорядок, и его легче читать. Избегайте лишних синтаксических конструкций, если это не уточняется дополнительно.
Используйте сравнение с образцом в определении функций, когда это необходимо; Вместо
list map { item =>
item match {
case Some(x) => x
case None => default
}
}
лучше написать так
list map {
case Some(x) => x
case None => default
}
Видно, что элементы списка сейчас отображаются более ясно — дополнительно уточнять ничего не нужно.
Используйте ScalaDoc, чтобы предоставлять документацию по API. Используйте следующий стиль:
/**
* ServiceBuilder builds services
* ...
*/
вместостандартного стиля ScalaDoc:
/** ServiceBuilder builds services
* ...
*/
Не прибегайте к ASCII искусству или другим визуальным украшениям. Документируйте API, но не добавляйте ненужных комментариев. Если вы добавляете комментарии, чтобы объяснить поведение вашего кода, сначала спросите себя, может ли код быть переписан так, чтобы стало очевидным, что он делает. Лучше предпочесть “Очевидно, это работает” вместо “Это работает, очевидно” (цитата Энтони Хоара).
(прим. переводчика: “Есть два метода создания программного обеспечения. Один из них — сделать программу настолько простой, что, очевидно, в ней нет недостатков. И другой, сделать приложение настолько сложным, что в нем не видно явных недостатков.” - Энтони Хоар выдержка из лекции, Премия Тьюринга)
Основной целью системы типов является выявление ошибок программирования. Система типов эффективно обеспечивает определенную форму статической проверки, что позволяет нам получать определенный набор неизменных параметров о нашем коде, который компилятор может проверить. Система типов, конечно, обеспечивает и другие преимущества, но проверка ошибок является ее основной целью.
Использование системы типов должно отражать эту цель, но мы должны не забывать и о читателе: разумное использование типов может служить повышением ясности. Все слишком усложнять - значит запутывать остальных.
Мощная система типов в Scala является результатом общих усилий различных академических опытов и разработок (например, [Scala программирование на уровне системы типов] (http://apocalisp.wordpress.com/2010/06/08/type-level-programming-in-scala/)). Несмотря на то, что это увлекательная академическая статья, эти методы редко находят полезное применение в реальном коде приложений. Их можно избегать.
Хотя Scala позволяет опускать их, такие аннотации обеспечивают хорошую документацию: это особенно важно для публичных методов. Там где возвращаемый тип метода очевиден, их можно опустить.
Это особенно важно при создании экземпляров объектов с миксинами(Mixins), так как компилятор Scala создает тип синглтон(singleton) для них. Например, make в примере:
trait Service
def make() = new Service {
def getId = 123
}
не имеет возвращаемого типа Service; компилятор создает Object with Service{def getId: Int}. Вместо того, чтобы использовать явную аннотацию:
def make(): Service = new Service{}
В настоящее время автор может смешивать множество трейтов(traits) без изменения общедоступного типа make, делая возможность легче управлять обратной совместимостью.
Расхождение возникает, когда обобщенные типы объединены с выделением подтипов. Они определяют, как выделение подтипов типа contained относится к выделению подтипов типа container. Поскольку в Scala имеется определенное соглашение по комментированию, то авторы общих библиотек - особенно коллекций - должны активно писать комментарии. Такие комментарии важны для удобства работы с общим кодом, но неверные комментарии могут быть опасны.
Инварианты - усовершенствованный, но необходимый компонент системы типов Scala, и должны использоваться широко (и правильно), поскольку это помогает приложению в выделении подтипов.
Коллекции Immutable должны быть ковариантны. Методы, которые получают contained тип должны быть “понижены”(“downgrade”) до соответствующей коллекции:
trait Collection[+T] {
def add[U >: T](other: U): Collection[U]
}
Mutable коллекции должны быть инвариантны. Ковариация обычно бессмысленна с изменяемыми(mutable) коллекциями. Рассмотрим
trait HashSet[+T] {
def add[U >: T](item: U)
}
и следующую иерархию типов:
trait Mammal
trait Dog extends Mammal
trait Cat extends Mammal
Допустим, у нас сейчас есть хеш-коллекция из объектов Собака
val dogs: HashSet[Dog]
создаем хеш-коллекцию Млекопитающих и добавляем в колллекцию объект Кошка
val mammals: HashSet[Mammal] = dogs
mammals.add(new Cat{})
Теперь эта хеш-коллекция не является коллекцией объектов Собака!
(прим. переводчика: Подробнее о ковариантности и контрвариантности)
Используйте псевдонимы типов, когда они позволяют удобно именовать или разъяснять цели, но не искажают типы, которые и так очевидны.
() => Int
данная запись более понятна чем
type IntMaker = () => Int
IntMaker
так как это короче и используется общий тип, однако
class ConcurrentPool[K, V] {
type Queue = ConcurrentLinkedQueue[V]
type Map = ConcurrentHashMap[K, Queue]
...
}
более полезен, так как передает цель и улучшает краткость.
Не используйте разделение на подклассы, когда псевдоним делает тоже самое
trait SocketFactory extends (SocketAddress => Socket)
SocketFactory это функция которая создает Socket. Использование псевдонима
type SocketFactory = SocketAddress => Socket
более правильно. Теперь мы можем обеспечить функциональные идентификаторы для значений типаSocketFactory, а также использовать композицию функций:
val addrToInet: SocketAddress => Long
val inetToSocket: Long => Socket
val factory: SocketFactory = addrToInet andThen inetToSocket
Псевдонимы типов связаны с именами, которые стоят выше в иерархии, при помощи объектов пакета:
package com.twitter
package object net {
type SocketFactory = (SocketAddress) => Socket
}
Обратите внимание на то, что псевдонимы, это не новые типы - они эквивалентны синтаксической замене типа новым именем.
Неявные преобразования являются мощной возможностью системы типов, но они должны использоваться там, где необходимы. Они усложняют правила преобразования трудоемкими — если по простому, то лексическим сравнением — чтобы понять, что на самом деле происходит. Обычно неявные преобразования используются в следующих ситуациях:
МанифестовЕсли действительно хотите использовать неявные преобразования, прежде всего спросите себя, есть ли способ достигнуть той же цели без их помощи.
Не используйте неявные преобразования, чтобы сделать автоматическое преобразование между похожими типами данных (например, преобразование списка в поток); это лучше сделать явно, потому что у типов есть различная семантика, и читатель должен остерегаться подобных реализаций.
У Scala есть универсальная, богатая, мощная, и прекрасно составленная библиотека коллекций; коллекции - высокоуровневые реализации и они представляют собой большой набор различный операций. Множество действий с коллекциями и преобразования над ними могут быть выражены кратко и четко, но небрежное применение функций может привести к противоположному результату. Каждый Scala-программист должен прочитать Сollections design document; он даст большее понимание при работе с библиотекой коллекций в Scala.
Всегда используйте самую простую коллекцию, которая соответствует вашим потребностям потребностям.
Библиотека коллекций очень большая: в дополнение к сложной
иерархии - корнем которой является Traversable[T] - существуют
immutable и mutable варианты для большинства коллекций. Несмотря на сложность, на следующей диаграмме содержатся важные
различия между immutable и mutable иерархиями
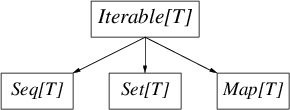
Iterable[T] - это любая коллекция, элементы которой могут быть проитерированы, она имеет метод iterator(а также метод foreach).Seq[T]- это коллекция, элементы которой отсортированы,Set[T]- является аналогом математического множества (неупорядоченная коллекция уникальных элементов), и Map[T] - который представляет собой неотсортированный ассоциативный массив.
Предпочитительнее использовать immutable коллекции.* Они применимы в большинстве случаев, и делают программу проще и прозрачнее,а также потокобезопасной.
Используйте mutable пространство имен явно.* Не импортируйте
scala.collection.mutable._, а ссылку на set, лучше сделать так
import scala.collections.mutable val set = mutable.Set()
так становится ясно, что используется mutable вариант
Используйте стандартный конструктор для коллекций.* Всякий раз, когда вам нужна упорядоченная последовательность (и не обязательно связанный список), используйте конструктор Seq(), или ему подобный вариант:
val seq = Seq(1, 2, 3) val set = Set(1, 2, 3) val map = Map(1 -> “one”, 2 -> “two”, 3 -> “three”)
Этот стиль отделяет семантику коллекции от ее реализации, позволяя библиотеке коллекций использовать наиболее подходящий тип: если вам нужен Map, не обязательно использовать Красно-черное дерево(Red-Black Tree). Кроме того, стандартные конструкторы будут часто использовать специализированные представления: например, Map() будет использовать объект с 3 полями для объектов с 3 ключами(Map3).
В заключение, к сказанному выше: в ваших собственных методах и конструкторах старайтесь использовать самую универсальную коллекцию. Обычно это сводится к одной из приведенных: Iterable, Seq, Set, или Map. Если ваш метод нуждается в последовательности, используйте Seq[T], а не List[T].
Функциональное программирование призывает к цепочечным преобразованиям immutable коллекций для получения желаемого результата. Это часто приводит к очень коротким решениям, но также может ввести в заблуждение читателя - часто трудно понять намерения автора, или отслеживать все промежуточные результаты, которые подразумеваются. Например, предположим, что мы хотим подсчитать голоса за разные языки программирования из определенного набора (язык, число голосов); показывая их, в порядке убывания числа голосов, мы могли бы написать:
val votes = Seq(("scala", 1), ("java", 4), ("scala", 10), ("scala", 1), ("python", 10))
val orderedVotes = votes
.groupBy(_._1)
.map { case (which, counts) =>
(which, counts.foldLeft(0)(_ + _._2))
}.toSeq
.sortBy(_._2)
.reverse
это кратко и правильно, но почти любому читателю нужно время, чтобы восстановить в голове первоначальные намерения автора. Стратегия, которая призвана уточнить решение использование промежуточных результатов и параметров:
val votesByLang = votes groupBy { case (lang, _) => lang }
val sumByLang = votesByLang map { case (lang, counts) =>
val countsOnly = counts map { case (_, count) => count }
(lang, countsOnly.sum)
}
val orderedVotes = sumByLang.toSeq
.sortBy { case (_, count) => count }
.reverse
код является почти столь же кратким, но гораздо более четко описывает происходящие превращения (благодаря именованным промежуточным значениям), и структуры данных с которыми работает программа (именованные параметры). Если вы беспокоитесь о засорении пространства имен, применяя этот стиль, используйте группировку выражений с помощью {}:
val orderedVotes = {
val votesByLang = ...
...
}
Высокоуровневые библиотеки коллекций (как обычно и с высокоуровневыми конструкциями), делают определение производительности более трудоемким: чем дальше вы отклоняетесь от указания конкретных команд компьютеру - другими словами, императивного стиля - тем тяжелее предсказать точное значение производительности участка кода. Обосновать правильность, однако, обычно проще; также повышается удобство чтения кода. Со Scala ситуация осложнена средой исполнения Java; Scala скрывает операции упаковки/распаковки от нас, но они могут серьезно влиять на производительность или оказывать противоположное действие.
Прежде, чем сфокусироваться на низкоуровневых деталях, удостоверьтесь, что используете коллекцию, подходящую для данного случая. Удостоверьтесь, что ваша структура данных не имеет неожиданной асимптотической сложности. Возникающие при работе сложности для разных Scala коллекций описаны здесь.
Первое правило оптимизации производительности состоит в том, чтобы понять почему ваше приложение медленно работает. Не стоит действовать без оглядки; профилируйте^ Yourkit - неплохой профилировщик] приложение перед тем как действовать дальше. Фокусируйтесь сначала на интенсивно используемых циклах и больших структурах данных. Чрезмерные усилия на оптимизацию обычно тратятся впустую. Помните принцип Кнута: “Преждевременная оптимизация - корень все зол.”
Очень часто целесообразно использовать низкоуровневые коллекции в ситуациях где требуется лучшая производительность или иметь задел эффективности на будущее. Используйте массивы вместо списков для больших последовательностей (неизменяемая Vector коллекция обеспечивает похожий интерфейс для массивов); и используйте буферы вместо конструирования последовательности, когда стоят вопросы производительности.
Используйте scala.collection.JavaConverters для взаимодействия с коллекциями Java. Эта коллекция неявно добавляет методы преобразования asJava и asScala. Их использование гарантирует, что такие преобразования являются явными, помогая читателю:
import scala.collection.JavaConverters._
val list: java.util.List[Int] = Seq(1,2,3,4).asJava
val buffer: scala.collection.mutable.Buffer[Int] = list.asScala
Современные сервисы обладают высоким уровнем параллелизма - серверы выполняют 10–100 тысяч одновременных операций - и их обработка подразумевают сложность, которая является центральной темой в надежных программных системах.
Потоки являются средством выражения параллелизма: они дают вам независимые контексты выполнения с общей разделяемой памятью, которая управляется операционной системой. Тем не менее, создание потоков является затратной операцией в Java и этим ресурсом необходимо управлять, как правило, с использованием пулов. Это создает дополнительные сложности для программиста, а также обладает высокой степенью связности: трудно отделить логику приложения от используемых им основных ресурсов.
Эта сложность особенно заметна при создании сервисов, которые имеют высокую степень параллелизма: каждый приходящий результат запроса в множество всех запросов на каждый уровень системы. В таких системах, пулы потоков должны быть организованы таким образом, чтобы они быди сбалансированы в зависимости от количества запросов на каждом уровне: беспорядок в одном пуле потоков негативно влияет на другие.
Надежная система должна также не упускать из виду тайм-ауты и отказы, оба этих элемента требуют введения дополнительного «контроля» потоков, тем самым усложняя проблему еще больше. Заметим, что если бы потоки были более дешевыми, то эти проблемы стали бы меньше: необходимость в пулах, тайм-аутах потоков можно было бы отбросить, и никаких дополнительных ресурсов для управления не потребовалось бы.
Таким образом, управление ресурсами ставит под угрозу модульность.
Используйте futures(актор с возможностью блокировки создающего его потока, если создающий поток запросил результат вычисления - прим. переводчика) для управления параллелизмом. Они позволяют отделить параллельные операции от управления ресурсами: например, Finagle объединяет параллельные операции в несколько потоков эффективным образом. Scala имеет легковесный синтаксис замыканий, поэтому futures вводят немного синтаксического сахара; и они становятся все более популярны среди программистов.
Futures позволяют программисту выразить параллельные вычисления в декларативном стиле, скомпоновать, и управлять источником ошибки. Эти качества убедили нас в том, что они особенно хорошо подходят для использования в функциональных языках программирования, где подобный стиль поощряется.
Изменяйте futures вместо создания собственных. Futures позволяют поймать ошибку, определить сигнал отказа, и позволяет программисту не думать о релизации модели памяти в Java. Осторожный программист может написать следующее решение для RPC последовательности из 10 элементов, а затем напечатать результаты:
val p = new Promise[List[Result]]
var results: List[Result] = Nil
def collect() {
doRpc() onSuccess { result =>
results = result :: results
if (results.length < 10)
collect()
else
p.setValue(results)
} onFailure { t =>
p.setException(t)
}
}
collect()
p onSuccess { results =>
printf("Got results %s\n", results.mkString(", "))
}
Программист должен убедиться, что RPC ошибки будут распространяться дальше,
объединяя код и контроль потока выполнения; хуже того, этот код неверен! Без объявления переменной results, мы не можем гарантировать, что results содержит предыдущее значение на каждой итерации. Модель памяти Java не так проста как кажется, но, к счастью, мы можем избежать всех этих ошибок с помощью
декларативного стиля:
def collect(results: List[Result] = Nil): Future[List[Result]] =
doRpc() flatMap { result =>
if (results.length < 9)
collect(result :: results)
else
result :: results
}
collect() onSuccess { results =>
printf("Got results %s\n", results.mkString(", "))
}
Мы используем flatMap в последовательности операций и сохраняем результат в список, пока идут вычисления. Это общая идея функциональных языков программирования
реализована в Futures. Для этого требуется меньше заготовок, возникает меньше ошибок, а также читается лучше.
Используйте Futures комбинаторы. Future.select, Future.join, и Future.collect реализуют общие шаблоны при работе над несколькими Futures, которые должны быть объединены.
С параллельными коллекциями связано множество мнений, тонкостей, догм, страха, неуверенности и сомнения. В большинстве практических ситуаций, они не являются проблемой: Всегда начинайте с самой простой, самой невзрачной, и стандартной коллекции, которая послужит поставленной цели. Не используйте параллельную коллекцию до того, как вы будете знать, что синхронизированный вариант коллекции не работает: JVM имеет современные механизмы, чтобы сделать синхронизацию дешевой операцией, так что их эффективность может вас удивить.
Если необходимо использовать immutable коллекцию, используйте - она совершенно прозрачна, поэтому рассуждать о них в контексте параллельных вычислений очень просто. Изменения в immutable коллекциях, как правило, выполняются путем обновления ссылки на текущее значение (в var ячейке или
AtomicReference). Необходимо соблюдать осторожность, чтобы верно это применять: атомы должны быть повторно объявлены, и переменные должны быть объявлены на лету в порядке их объявления в других потоках.
Mutable параллельные коллекции имеют сложную семантику, и используют тонкости модели памяти в Java, поэтому убедитесь, что вы понимаете последствия - особенно при распространении обновлений - прежде чем начинать использовать их. Синхронные коллекции тоже неплохой вариант: операции, такие как getOrElseUpdate не могут быть правильно реализованы для параллельных коллекций, и создание сложных коллекций особенно подвержено ошибкам.
Программы в функциональном стиле, как правило, требуют меньше традиционных управляющих структур, да и читать код лучше, когда он написан в декларативном стиле. Это обычно означает, разделение вашей логики на несколько небольших методов или функций, и склеивание их вместе с match выражениями. Функциональные программы также имеют тенденцию быть более
ориентированными на выражения: ветви условных выражений для значений того же типа, for (..) yield вычисление дополнений, и рекурсия являются обычным делом.
Формулировка проблемы в терминах рекурсии обычно упрощает ее, и если применяется оптимизация хвостовой рекурсии (которая может быть проверена с помощью аннотации @tailrec), компилятор преобразует код в обычный цикл.
Рассмотрим довольно стандартную императивную реализацию кучи fix-down:
def fixDown(heap: Array[T], m: Int, n: Int): Unit = {
var k: Int = m
while (n >= 2*k) {
var j = 2*k
if (j < n && heap(j) < heap(j + 1))
j += 1
if (heap(k) >= heap(j))
return
else {
swap(heap, k, j)
k = j
}
}
}
Каждый раз, при входе в цикл, мы работаем с состоянием предыдущей итерации. Значением каждой переменной является результат вычисления функции определенной ветви выполнения, и значение возвращается в середине цикла, если был найден верный результат вычисления (внимательный читатель найдет похожие аргументы в Дейкстры “О вреде оператора Go To”).
Рассмотрим реализацию (хвостовой) рекурсии[1]:
@tailrec
final def fixDown(heap: Array[T], i: Int, j: Int) {
if (j < i*2) return
val m = if (j == i*2 || heap(2*i) < heap(2*i+1)) 2*i else 2*i + 1
if (heap(m) < heap(i)) {
swap(heap, i, m)
fixDown(heap, m, j)
}
}
здесь каждая итерация начинается с чистого листа, и нет никаких ссылочных полей: инвариантов достаточно. Об этом гораздо легче рассуждать, и этот код проще для чтения. Не существует потери производительности: поскольку метод является хвостовой рекурсией, компилятор переводит его в обычный цикл.
Это не означает, что императивные структуры бесполезны.
Во многих случаях они хорошо подходят для прекращения вычислений вместо условных переходов для всех возможных вариантов окончания вычислений: ведь в приведенном выше fixDown, return используется для досрочного прекращения, если мы в конце кучи.
Возврат значений может быть использован, чтобы сократить количество ветвлений и установить инварианты. Он помогает читателю за счет уменьшения вложенности и делает легче рассуждения о правильности последующего кода (доступ к элементу массива не может происходить за границей массива). Это особенно полезно в “guard” выражениях:
def compare(a: AnyRef, b: AnyRef): Int = {
if (a eq b)
return 0
val d = System.identityHashCode(a) compare System.identityHashCode(b)
if (d != 0)
return d
// slow path..
}
Используйте return для уточнения и улучшения читаемости, но не так, как в императивных языках; избегайте его использования для возврата результатов вычислений. Вместо
def suffix(i: Int) = {
if (i == 1) return "st"
else if (i == 2) return "nd"
else if (i == 3) return "rd"
else return "th"
}
лучше использовать:
def suffix(i: Int) =
if (i == 1) "st"
else if (i == 2) "nd"
else if (i == 3) "rd"
else "th"
но использование выражения match подходит лучше:
def suffix(i: Int) = i match {
case 1 => "st"
case 2 => "nd"
case 3 => "rd"
case _ => "th"
}
Обратите внимание, что использование returns тоже имеет свою цену: при использовании внутри замыкания,
seq foreach { elem =>
if (elem.isLast)
return
// process...
}
в байт-коде это реализовано в виде пары исключений catching/throwing, использование которых в реальном коде, влияет на производительность.
for и генераторыfor обеспечивает краткий и естественный способ для циклической обработки данных и их накопления. Это особенно полезно, когда обрабатывается много последовательностей.
Синтаксис for противоречит основному механизму выделения и управления замыканиями. Это может привести к непредвиденным расходам и двусмысленности, например
for (item <- container) {
if (item != 2) return
}
. LP может привести к ошибке выполнения, если произойдет задержка при вычислении container, что делает return не локальным!
По этим причинам, обычно предпочтительнее, вызвать foreach,
flatMap, map и filter напрямую - но стоит использовать for для того, чтобы прояснить вычисления.
require и assertrequire и assert, оба оператора описаны в документации. Оба полезны для ситуаций, в которых система типов не может определить нужный вариант типа. assert, используется для инвариантов, которые предполагаются в коде (или
внутреннем или внешнем), например
val stream = getClass.getResourceAsStream("someclassdata")
assert(stream != null)
В то время как require используется для представления API контрактов:
def fib(n: Int) = {
require(n > 0)
...
}
Программирование ориентированное на значение дает много преимуществ, особенно когда используется в сочетании с конструкциями функционального программирования. Этот стиль делает ставку на преобразовании значений вместо изменения состояния, возвращая код, который более прозрачен, обеспечивая больше инвариантов, а значит и легче в понимании. Case классы, сопоставление с образцом, несвязность, вывод типов, и легковесное создание замыканий и методов образуют синтаксис, который является предметом обсуждений.
Case классы представляют собой АТД(алгебраический тип данных): они полезны для моделирования большого числа структур данных и обеспечивают более короткий код с мощными инвариантами, особенно при использовании сопоставления с образцом. Сопоставление с образцом реализует исчерпывающий анализ, обеспечивая равномерные статические гарантии.
При использовании следующего примера с использованием АТД и Case классов:
sealed trait Tree[T]
case class Node[T](left: Tree[T], right: Tree[T]) extends Tree[T]
case class Leaf[T](value: T) extends Tree[T]
тип Tree[T]имеет два конструктора: Node и Leaf. Объявление типа sealed позволяет компилятору сделать исчерпывающий анализ, поскольку конструкторы не могут быть добавлены в другом исходном файле.
Вместе с использованием сопоставления с образцом, мы получаем краткие и “очевидно правильные” результаты моделирования в коде:
def findMin[T <: Ordered[T]](tree: Tree[T]) = tree match {
case Node(left, right) => Seq(findMin(left), findMin(right)).min
case Leaf(value) => value
}
В то время как рекурсивные структуры, такие как деревья представляют собой классические реализации АТД, областей их полезного применения намного больше. Несвязные объединения, в частности, легко моделируется с помощью абстрактных типов данных; они часто встречаются в различных состояниях машины.
Тип Option - это контейнер, который либо пуст (None), либо полон (Some(value)). Он обеспечивает безопасную альтернативу использованию null, и должен быть использован вместо null всякий раз, когда это возможно. Эти типы являются коллекциями (содержащими не более одного элемента) и они используют методы коллекций - чаще используйте их!
Пишите
var username: Option[String] = None
...
username = Some("foobar")
вместо
var username: String = null
...
username = "foobar"
первый вариант безопаснее: тип Option статически проверяет что Username должен быть заранее проверен на пустоту.
Применение в условных конструкциях Option значений должно быть сделано с помощью foreach, вместо
if (opt.isDefined)
operate(opt.get)
пишите
opt foreach { value =>
operate(value)}
Стиль может показаться странным, но обеспечивает большую безопасность (мы не вызываем исключительно get) и краткость. Если есть два варианта выполнения, то при использовании сопоставления с образцом получим:
opt match {
case Some(value) => operate(value)
case None => defaultAction()
}
но если все варианты ложные, то для значений по умолчанию, используйте getOrElse
operate(opt getOrElse defaultValue)
Не злоупотребляйте Option: если имеется значение по
умолчанию - Null Object - используйте его.
Option также предоставляет удобный конструктор для упаковки nullable значения:
Option(getClass.getResourceAsStream("foo"))
выражение является Option[InputStream] который может принимать значение None, в этом случае getResourceAsStream должен возвратить null.
Сопоставление с образцом (x match { ...) широко распространено в хорошо написанном Scala коде: оно осуществляет условное выполнение, разбор конструкций, и все это в одной конструкции. При его использовании также повышается четкость и безопасность.
Используйте сопоставление с образцом для реализации переключения типов:
obj match {
case str: String => ...
case addr: SocketAddress => ...
Сопоставление с образцом лучше всего работает в сочетании с разбором конструкций (например, работе с Case классами), вместо
animal match {
case dog: Dog => "dog (%s)".format(dog.breed)
case _ => animal.species
}
лучше написать
animal match {
case Dog(breed) => "dog (%s)".format(breed)
case other => other.species
}
Используйте custom extractors, но только с дополнительным конструктором (apply), в противном случае их использования может быть неуместным.
Не используйте сопоставление с образцом для вычисления условий, когда имеет смысл использовать стандартные значения. Библиотеки коллекций обычно предоставляют методы, которые возвращают Option; избегайте такого кода
val x = list match {
case head :: _ => head
case Nil => default
}
потому что
val x = list.headOption getOrElse default
так короче и больше соответствует цели
Scala предоставляет синтаксический сахар для определения PartialFunction:
val pf: PartialFunction[Int, String] = {
case i if i%2 == 0 => "even"
}
они могут использоваться вместе с orElse
val tf: (Int => String) = pf orElse { case _ => "odd"}
tf(1) == "odd"
tf(2) == "even"
Частичные функции исопльзуются во многих ситуациях и эффективно
кодируются с помощью PartialFunction, например, в качестве аргументов
методов
trait Publisher[T] {
def subscribe(f: PartialFunction[T, Unit])
}
val publisher: Publisher[Int] = ..
publisher.subscribe {
case i if isPrime(i) => println("found prime", i)
case i if i%2 == 0 => count += 2
/* ignore the rest */
}
или в ситуациях, которые могли бы способствовать возврату Option
// Attempt to classify the the throwable for logging.
type Classifier = Throwable => Option[java.util.logging.Level]
все это может быть лучше выражено с помощью PartialFunction
type Classifier = PartialFunction[Throwable, java.util.Logging.Level]
так как это более компактно:
val classifier1: Classifier
val classifier2: Classifier
val classifier = classifier1 orElse classifier2 orElse { _ => java.util.Logging.Level.FINEST }
Разрушение связей тесно связано с сопоставлением с образцом; используется тот же механизм, но применяется, когда есть только один вариант (чтобы не сгенерировать исключение). Разрушение связей особенно полезно для кортежей и Case классов.
val tuple = ('a', 1)
val (char, digit) = tuple
val tweet = Tweet("just tweeting", Time.now)
val Tweet(text, timestamp) = tweet
Поля в Scala вычисляются при необходимости, если val имеет префикс
lazy. Поэтому поля и методы в Scala подобны (поля как бы private[this]):
lazy val field = computation()
это сокращение для
var _theField = None
def field = if (_theField.isDefined) _theField.get else {
_theField = Some(computation())
_theField.get
}
где, результаты вычисляются и запоминаются. Используйте ленивые поля для этих случаев, но избегайте использования ленивых вычислений, когда ленивые вычисления требуются по смыслу. В этих случаях лучше производить вычисления явно, поскольку можно точно произвести оценку, и побочные эффекты могут контролироваться более точно.
Ленивые поля являются потокобезопасными.
Параметры методов могут быть переданы по имени, то есть параметр принимает не значение, а вычисление, которое может повторяться. Это функция должна применяться с осторожностью; вызывающая функция может ожидать передачу по значению, но ответ ее удивит. Способ применения этой особенности - это построение обычных синтаксических DSL - например, могут быть сделаны новые конструкции управления, чтобы выглядеть так же, как и родные особенности языка.
Используйте передачу по имени управляющих конструкций, когда для вызывающей функции очевидно, что передается в этот “блок”, вместо результата каких-то неожиданных вычислений. Записывайте передачу по имени в крайней позиции последнего списка аргументов. При использовании передачи по имени, убедитесь, что метод назван очевидным образом для вызывающей функуции, которая передает аргумент.
Если вы хотите, чтобы значения вычислялись несколько раз, и, особенно, когда вычисление имеет побочные эффекты, используйте явные функции:
class SSLConnector(mkEngine: () => SSLEngine)
ваше намерение остается очевидным и для вызывающей функции это не будет сюрпризом
flatMapflatMap - сочетает в себе map и flatten - заслуживающие особого внимания, потому что они обладают небольшой мощью, но очень полезны. Подобно map, она доступна в нетрадиционных коллекциях, таких как Future и Option. Поведение функции
раскрывается при описании; например Container[]
flatMap[B](f: A => Container[B]): Container[B]
flatMap вызывает функцию f для элемента(ов) из коллекции создавая новую коллекцию, из всех тех, которые дают нужный результат. Например, чтобы получить все перестановки двух символьных строк, у которых нет общих символов, напишем дважды:
val chars = 'a' to 'z'
val perms = chars flatMap { a =>
chars flatMap { b =>
if (a != b) Seq("%c%c".format(a, b))
else Seq()
}
}
что эквивалентено, но более кратко и понятно (что само по себе —грубый— синтаксический сахар для написанного выше), этому коду:
val perms = for {
a <- chars
b <- chars
if a != b
} yield "%c%c".format(a, b)
flatMap часто полезна при работе с Option - она позволяет
свернуть цепочки вызовов до одного,
val host: Option[String] = ..
val port: Option[Int] = ..
val addr: Option[InetSocketAddress] =
host flatMap { h =>
port map { p =>
new InetSocketAddress(h, p)
}
}
данный пример также кратко можно написать с использованием for
val addr: Option[InetSocketAddress] = for {
h <- host
p <- port
} yield new InetSocketAddress(h, p)
Использование flatMap в Future обсуждается в
разделе futures.
Большая часть возможностей Scala обеспечивается благодаря объектной системе. Scala является чистым языком в этом смысле, потому что все элементы являются объектами, нет различия между примитивными типами и составными. Scala также имеет примеси (Mixins), позволяющие более четкое построение модулей, которые можно гибко собрать на этапе компиляции со всеми преимуществами статической проверки типов.
Основная идея системы примесей в том, чтобы избежать необходимости в традиционном построение зависимостей. Кульминацией этого “компонентного стиля” программирования является the cake pattern.
На своем опыте мы обнаружили, что Scala на самом деле удаляет большую часть синтаксических издержек “классического” (в конструкторе) внедрения зависимостей, и мы можем это использовать это: более ясное описание, зависимости все еще закодированы в типе, а конструкция класса так синтаксически проста, что это становится незаметно. Это скучно и просто, и это работает. Используйте внедрение зависимостей для модульного построения программы, и в частности предпочитайте композицию наследованию - это приведет к более модульным и легко тестируемым программам. Если возникает ситуация, когда требуется наследование, то спросите себя: как бы вы спроектировали программу, если бы язык не имел такой возможности, как наследование? Ответ может быть не так прост.
Для внедрения зависимостей обычно используются трейты(traits),
trait TweetStream {
def subscribe(f: Tweet => Unit)
}
class HosebirdStream extends TweetStream ...
class FileStream extends TweetStream ..
class TweetCounter(stream: TweetStream) {
stream.subscribe { tweet => count += 1 }
}
Они обычно исопользуются для внедрения фабрик - объектов, которые генерируют другие объекты. В этом случае предпочтительно использовать более простые функции вместо специализированных фабрик типов.
class FilteredTweetCounter(mkStream: Filter => TweetStream) {
mkStream(PublicTweets).subscribe { tweet => publicCount += 1 }
mkStream(DMs).subscribe { tweet => dmCount += 1 }
}
Внедрение зависимостей вовсе не исключает возможности использования общих интерфейсов, или релизации общего кода в трейтах. Совсем наоборот - использование трейтов настоятельно рекомендуется именно по этой причине: несколько интерфейсов (трейтов) могут быть реализованы в конкретном классе, а общий код может быть использован во всех таких классах.
Старайтесь писать трейты короткими и простыми: но не стоит разделять функциональности между трейтами, думайте о них, как о небольших кусочках, которые связаны друг с другом. Например, представьте, что у вас есть то, что может сделать IO:
trait IOer {
def write(bytes: Array[Byte])
def read(n: Int): Array[Byte]
}
разделите код на два поведения:
trait Reader {
def read(n: Int): Array[Byte]
}
trait Writer {
def write(bytes: Array[Byte])
}
или объедините их вместе, чтобы получить то, что было в IOer: new Reader with Writer… минимализм трейта приводит к простоте и более "чистой" модульности.
Скала имеет очень выразительные модификаторы видимости. Важно использовать их, так как они определяют то, что представляет собой публичный API. Публичные API должны быть ограничены так, чтобы пользователи случайно не полагались на реализацию деталей и предел возможностей автора менять их: они имеют решающее значение при постороение хорошей модульности. Как правило, гораздо проще расширять публичные API, чем их сокращать. Плохие аннотации также могут подорвать обратную бинарную совместимость вашего кода.
private[this]Член класса помеченный как private,
private val x: Int = ...
видим для всех экземпляров этого класса (но не и подклассов). В большинстве случаев вам нужен private[this].
private[this] val: Int = ..
который ограничивает видимость для конкретного экземпляра.Компилятор Scala также может переводить private[this] в простое поле для доступа (поскольку доступ ограничен для статически определенного класса), которое иногда может помочь при оптимизации производительности.
Общепринятая в Scala практика по созданию класса синглтона, например
def foo() = new Foo with Bar with Baz {
...
}
В таких ситуациях, видимость может быть ограничена, при объявлении возвращаемого типа:
def foo(): Foo with Bar = new Foo with Bar with Baz {
...
}
где вызывающие foo() участки кода будут ограничены с помощью (Foo with Bar) для возвращаемого экземпляра.
Не используйте структурных типов в обычных случаях. Они являются удобным и мощным средством, но к сожалению не имеют эффективной реализации для JVM. Однако - в связи с особенностями реализации - они обеспечивают очень краткое выражение для написания отражений(reflection).
val obj: AnyRef
obj.asInstanceOf[{def close()}].close()
Мы тратим много времени на настройку сборщика мусора в реальном коде. Проблемы сборщика мусора в значительной степени аналогичны проблемам в Java, хотя с идеалогической точки зрения код Scala имеет тенденцию генерировать больше (короткоживущего) мусора, чем подобный код на Java - все это побочный продукт функционального стиля. Сборщик мусора обычно делает это без проблем так как короткоживущий мусор эффективно собирается в большинстве случаев.
Прежде чем пытаться бороться с проблемами производительности сборщика мусора, посмотрите это Выступление Аттилы, который иллюстрирует некоторый наш опыт по настройке сборщика мусора.
В Scala собственно вашим единственным инструментом облегчения проблем со сборщиком мусора является создание меньшего количества мусора, но не стоит дествовать без предварительных данных! Пока вы не сделали того, что явно ухудшит ситуацию, используйте различные инструменты профилирования Java - Наши собственные инструменты включают heapster и gcprof.
Когда мы пишем код на Scala, который используется в Java, мы уверены, что эта возможность осталась из чисто идеалогическох соображений. Обычно для этого не требуется лишних усилий - классы и чистые трейты в точности эквивалентны их Java коллегам - но иногда нужно предоставить некоторые Java API. Хороший способ получить это для вашего библиотечного Java API, это написать юнит тест в Java (только для компиляции), это также обеспечит то, что поведение вашей Java библиотеки остается стабильным с течением времени, потому что компилятор Scala может быть неустойчив в этом отношении.
Трейты, которые реализуют некоторый функционал, не пригодны для непосредственного использования в Java: для этого нужно расширить абстрактный класс с трейтом.
// Не используется напрямую в Java
trait Animal {
def eat(other: Animal)
def eatMany(animals: Seq[Animal) = animals foreach(eat(_))
}
// А так можно:
abstract class JavaAnimal extends Animal
Наиболее важными стандартными библиотеками в Twitter являются Util и Finagle. Util должна рассматриваться как расширение для стандартной библиотеки Scala и Java, предоставляя недостающую функциональность и более соответствует конкретной реализации. Finagle - это наша RPC система, ядро распределенных системных компонентов.
Futures обсуждались коротко в разделе о параллельных вычислениях. Они являются центральным механизмом координации асинхронных процессов и широко распространены в нашем кода и в ядре Finagle. Futures позволяют объединять одновременные события, а также упрощают рассуждения о высокопараллельных операциях. Их можно эффективно реализовать на JVM.
Futures в Twitter являются асинхронными, так что блокирование операций - в основном любой операции, может быть приостановлено при выполнении своим потоком; сетевой ввод-вывод и дисковый ввод-вывод, например - должны быть обработаны системой, что обеспечивают сами futures для результатов указанных операций. Finagle предоставляет такую систему для сетевого ввода-вывода.
Futures являются простыми и понятными: они ждут результата вычислений, которые еще не завершились. Они представляют собой просто контейнер - заполнитель. Вычисление может и не закончится, и это должно быть закодировано: Future может находится ровно в одном из 3-х состояний: в ожидании, провалено или завершено.
Давайте вернемся к тому, что мы подразумеваем под композицией: сочетание простых компонентов в более сложных. Самый распространенный пример, это функция композиции: Даны функции f и g, функция композиции (g∘f)(x) = g(f(x)) — сначала результат получаем применения x в f, и потом результат этого выражения применяется в g — может быть записано на Scala:
val f = (i: Int) => i.toString
val g = (s: String) => s+s+s
val h = g compose f // : Int => String
scala> h(123)
res0: java.lang.String = 123123123функция h будет композитной. Это новая функция, которая объединяет f и g.
Futures являются своего рода коллекцией - это контейнер из
0 или 1 элементов - и вы увидите, что они имеют стандартные
методы коллекций (например, map, filter, и foreach). С Future значение откладывается(deferred), результат применения любого из этих методов также откладывается, в
val result: Future[Int]
val resultStr: Future[String] = result map { i => i.toString }
функция { i => i.toString } не вызывается, пока целочисленное значение не становится доступно, и преобразвание коллекции resultStr также откладывается до этого момента.
Списки могут быть свернуты;
val listOfList: List[List[Int]] = ..
val list: List[Int] = listOfList.flatten
и тоже самое можно сделать для futures:
val futureOfFuture: Future[Future[Int]] = ..
val future: Future[Int] = futureOfFuture.flatten
с futures происходит задержка, реализация flatten — должна немедленно — вернуть future, который ждет завершения внешнего future (Future[Future[Int]]) и после этого выполняется внутренний (Future[Future[Int]]). Если внешний future завершается с ошибкой, свернутый future должен также завершиться с ошибкой.
Futures (подобны Спискам) также имеют flatMap; Future[A] объявление:
flatMap[B](f: A => Future[B]): Future[B]
который похож на комбинацию map и flatten, и можем реализовать это следующим способом:
def flatMap[B](f: A => Future[B]): Future[B] = {
val mapped: Future[Future[B]] = this map f
val flattened: Future[B] = mapped.flatten
flattened
}
Это мощная комбинация! С помощью flatMap мы можем определить Future который является результатом двух последовательных futures, второй future вычисляется на основе
результатов первого. Представьте себе, что мы должны были бы сделать два RPC для аутентификации пользователя (ID), то мы могли бы определить составную операцию следующим образом:
def getUser(id: Int): Future[User]
def authenticate(user: User): Future[Boolean]
def isIdAuthed(id: Int): Future[Boolean] =
getUser(id) flatMap { user => authenticate(user) }
Дополнительным преимуществом этого типа композиции является то, что есть встроенная обработка ошибок: future не возвратиться из isAuthed(..) если в одной из функций getUser(..) или authenticate(..) не пишется дополнительного кода для обработки ошибок.
Future методы обратного вызова (callback) (respond, onSuccess, onFailure, ensure) вернут новый future, который сцеплен со своим родителем. Этот future гарантировано будет завершен только после завершения своего родителя, что позволяет писать так:
acquireResource()
future onSuccess { value =>
computeSomething(value)
} ensure {
freeResource()
}
где freeResource() гарантированно будет выполнен после computeSomething, позволяя эмуляцию шаблона try .. finally.
Используйте onSuccess вместо foreach — он симметричен для onFailure это лучшее имя для подобного случая, и позволяет цепочечные вызовы.
Всегда старайтесь избегать Promise экземпляров напрямую: почти каждая задача может быть решена с помощью использования предопределенных комбинаций. Эти комбинации обеспечивают распространение ошибки и отказа, и в целом поощряют стиль программирования потоков данных, который обычно <href = “#Параллелизм-Futures”>устраняет необходимость синхронизации и управления объявлениями.
Код, написанный в стиле хвостовой рекурсии не способствует утечки области стека, позволяет эффективно реализовывать циклы в стиле потоков данных:
case class Node(parent: Option[Node], ...)
def getNode(id: Int): Future[Node] = ...
def getHierarchy(id: Int, nodes: List[Node] = Nil): Future[Node] =
getNode(id) flatMap {
case n@Node(Some(parent), ..) => getHierarchy(parent, n :: nodes)
case n => Future.value((n :: nodes).reverse)
}
Future определяют множество полезных методов: Use Future.value() и Future.exception() для создания заранее определенных futures. Future.collect(), Future.join() и Future.select() предоставляют комбинации, которые обращают многие futures в один (например, объединяются как часть операции сбора-разбора).
Futures реализуют слабую форму отказа. Вызов Future#cancel
непосредственно не прекращает вычисления, но вместо этого устанавливает триггер сигнал, который может быть запрошен процессом, который в конечном счете удовлетворит требованиям future. Отказ распространяется в противоположном
направлении, чем значения: сигнал “отказ”, установленный принимающим объектом распространяется до объекта, установившего этот сигнал. Объект, установивший сигнал, использует onCancellation и Promise слушать этот сигнал и действовать соответственно.
Это означает, что смысл отказа зависит от объекта, который его вызвал, и не существует реализации по умолчанию. Отказ - всего лишь подсказка.
Утилита Local предоставляет ссылочную ячейку, которая является локальной для конкретного future дерева диспетчеризации. Установка значения local делает это значение доступны для любого вычисления отложенного в том же потоке. Они, аналогичны locals потоков, за исключением того, что они не используются в потоках Java, а в дереве “future потоков”. Например, в
trait User {
def name: String
def incrCost(points: Int)
}
val user = new Local[User]
...
user() = currentUser
rpc() ensure {
user().incrCost(10)
}
user() в блоке ensure будет ссылаться на значение user, локальное во время добавления функции обратного вызова.
Как и в потоковых locals, Local могут быть очень удобны, но их следует почти всегда избегать: убедитесь, что проблема не может быть решена путем передачи данных везде явно, даже если это несколько обременительно.
Locals эффективно используются в базовых библиотеках для очень общих задач - работа с потоками через RPC, передача мониторов, создание «трассировки стека» для будущих обратных вызовов - там, где любое другое решение было бы слишком обременительными для пользователей. Locals почти не подходят в любой другой ситуации.
Работа параллельных систем сильно осложняется необходимостью координации доступ к общим данным и ресурсам.Акторы предоставляют одну из стратегий упрощения работы: каждый актор это последовательный процесс, который сохраняет свое собственное состояние и ресурсы, а данные передаются путем передачи сообщений другим акторам. Обмен данными требует взаимодействия между акторами.
Offer/Broker состоит из трех важных компонентов. Во-первых,
каналы связи (Broker) являются первым элементом - то есть, вы отправляете сообщения через Broker, а не актору напрямую. Во-вторых, Offer/Broker является синхронным механизмом: общение синхронизировано. Это значит, мы можем использовать Broker в качестве механизма координации: когда процесс a отправляет сообщение процессу b, оба процесса и a и b располагают состоянием системы. И наконец, связь может осуществляться выборочно: процесс может предложить несколько различных способов коммуникаций, а в итоге получит ровно один
из них.
Для того, чтобы поддерживать выборочные связи (а также другие соединения) в общем случае, мы должны отделить описание связи от процесса общения. Это то, что делает Offer - это постоянная величина, которая описывает связи, для выполнения коммуникации (действующей на Offer), мы синхронизируем процесс через метод sync()
trait Offer[T] {
def sync(): Future[T]
}
который возвращает Future[T], что дает возможность обменяться значениями, когда возникла связь.
Broker координирует обмен значениями через Offers - это канал связи
trait Broker[T] {
def send(msg: T): Offer[Unit]
val recv: Offer[T]
}
так что при создании двух Offers
val b: Broker[Int]
val sendOf = b.send(1)
val recvOf = b.recv
и sendOf и recvOf оба синхронизированы
// In process 1:
sendOf.sync()
// In process 2:
recvOf.sync()
обе Offers обменяются значением 1.
Выборочная связь осуществляется путем объединения нескольких Offers с помощью Offer.choose
def choose[T](ofs: Offer[T]*): Offer[T]
что дает новые Offers, которые, при синхронизации, получают только один из ofs — первая из них станет доступной для дальнейших действий. Когда их становится несколько, доступных одновременно, один из них выбирается случайным образом.
Объект Offer имеет ряд одноразовых Offers, которые используются для объединения Offer с Broker.
Offer.timeout(duration): Offer[Unit]
это Offer, который активируется после передачи данного периода времени (duration). Offer.never никогда не получит данного значения, и Offer.const(value) сразу получает заданное значение. Они полезны при объединении, когда используется выборочная свзяь. Например, чтобы использовать задержку по времени операции отправки:
Offer.choose(
Offer.timeout(10.seconds),
broker.send("my value")
).sync()
Выглядит заманчиво, если сравнивать Offer/Broker с SynchronousQueue, но они отличаются небольшими, но важными деталями. Offers могут быть составлены таким образом, что таких очередей просто не существует. Например, рассмотрим набор очередей, представленых как Broker:
val q0 = new Broker[Int]
val q1 = new Broker[Int]
val q2 = new Broker[Int]
Теперь давайте создадим общую очередь для чтения:
val anyq: Offer[Int] = Offer.choose(q0.recv, q1.recv, q2.recv)
anyq является Offer, который будет читать из первой доступной очереди. Обратите внимание, что anyq является все еще синхронизированной - кроме этого у нас еще есть основная очередь. Такая композиция просто не возможна с использованием очередей.
Пулы подключений очень распространены в сетевых приложениях, и они часто сложно реализованы - например, часто желательно иметь задержку при запрос из пула, так как различные клиенты имеют разные задержки запросов. Пулы сами по себе просты: мы поддерживаем очереди соединений, и мы обслуживаем ожидающие объекты, как только они приходят. С традиционными примитивами синхронизации, это обычно подразумевает сохранение двух очередей: одна из ожидающих (когда у них нет соединений), и одна а из соединений (при отсутствии ожидающих).
Используя Offer/Broker, мы можем выразить это вполне естественно:
class Pool(conns: Seq[Conn]) {
private[this] val waiters = new Broker[Conn]
private[this] val returnConn = new Broker[Conn]
val get: Offer[Conn] = waiters.recv
def put(c: Conn) { returnConn ! c }
private[this] def loop(connq: Queue[Conn]) {
Offer.choose(
if (connq.isEmpty) Offer.never else {
val (head, rest) = connq.dequeue
waiters.send(head) { _ => loop(rest) }
},
returnConn.recv { c => loop(connq enqueue c) }
).sync()
}
loop(Queue.empty ++ conns)
}
loop всегда будет сделкой, чтобы иметь возможность восстановления связи, но только Offer может отправить сообщение, когда очередь не пуста. Использование стойких очередей упрощает дальнейшие рассуждения. Взаимодействие с пулом идет через Offer, поэтому, если вызывающий объект хочет использовать тайм-аут, он может это сделать с помощью комбинаторов:
val conn: Future[Option[Conn]] = Offer.choose(
pool.get { conn => Some(conn) },
Offer.timeout(1.second) { _ => None }
).sync()
Никаких дополнительных телодвижений не требуется для реализации тайм-аутов, это связано с семантикой Offers: если выбран Offer.timeout, не требуется больше Offer получать информацию их пула - пул и вызывающая функция никак не могут одновременно получать и отправлять данные, особенно, для ожидающих Broker.
Часто бывает полезно - а иногда и значительно упрощает жизнь - представление параллельных программ в виде набора последовательных процессов, которые взаимодействуют синхронно. Offers и Brokers предоставляют набор инструментов, чтобы сделать это просто и единообразно. В самом деле, их применение выходит за рамки того, что можно считать “классическими” проблемами параллелизма - параллельное программирование (с помощью Offers/Broker) является полезным структурированным инструментом, таким же как подпрограммы, классы и модули.
Одним из этих примеров является Решето Эратосфена, который может быть представлен как последовательное применение фильтров для потоков целых чисел. Во-первых, мы должны иметь источник целых чисел:
def integers(from: Int): Offer[Int] = {
val b = new Broker[Int]
def gen(n: Int): Unit = b.send(n).sync() ensure gen(n + 1)
gen(from)
b.recv
}
integers(n) это просто Offer всех последовательных целых чисел, начиная с n. Затем нужно отфильтровать:
def filter(in: Offer[Int], prime: Int): Offer[Int] = {
val b = new Broker[Int]
def loop() {
in.sync() onSuccess { i =>
if (i % prime != 0)
b.send(i).sync() ensure loop()
else
loop()
}
}
loop()
b.recv
}
filter(in, p) возвращает Offer, который извлекает множество простых чисел p из in. В конце концов мы составляем наше решето:
def sieve = {
val b = new Broker[Int]
def loop(of: Offer[Int]) {
for (prime <- of.sync(); _ <- b.send(prime).sync())
loop(filter(of, prime))
}
loop(integers(2))
b.recv
}
loop() работает просто: он читает следующее (простое) число из of, потом применяет фильтр of, который вытаскивает это число. Так как loop - это рекурсия, то отфильтровывая последовательно простые числа, мы получваем наше решето. Теперь мы можем напечатать первые 10000 простых чисел:
val primes = sieve
0 until 10000 foreach { _ =>
println(primes.sync()())
}
Помимо того, что все сделано с помощью простых, базовых составляющих, этот подход дает вам решето: вам не нужна априорная информация, вычисляйте множество простых чисел, которые вам нужны, в дальнейшем повышая модульность.
Уроки в этом документе, принадлежат Scala сообществу в Twitter, - и я надеюсь, Я был верным летописцем.
Blake Matheny, Nick Kallen, Steve Gury, и Raghavendra Prabhu предоставили множество полезных советов и превосходных предложений