
forループと内包, require と assertflatMapScala は Twitter で使われている主要なアプリケーションプログラミング言語の一つだ。Twitter のインフラの大部分は Scala で書かれているし、我々の業務を支える大規模ライブラリをいくつか持っている。Scala は極めて効果的だが、一方で巨大な言語でもある。我々の経験では、Scala の適用には十分な注意が必要だ。落とし穴は何か? どの機能を活用して、どれを控えるべきか? いつ“純粋関数型のスタイル”を採用して、いつ避けるべきか? 言い換えるなら、我々が見出した“Scala の効果的 (effective) な使い方”とは何か? 本ガイドの目的は、我々の経験から抜き出された一連のベストプラクティスを提供することだ。Twitter では、主に Scala を分散システムを構成する大容量サービス群の作成に使っているので、我々の助言にはバイアスがかかっている。しかし、ここにあるアドバイスの大半は、他の問題領域へ自然に移し替えられるはずだ。これは規則ではない。だから逸脱は正当化されるべきだ。
Scala が提供するたくさんの道具は、簡潔な表現を可能にする。タイピングが減れば読む量が減り、大抵は読む量が減ればより速く読める。故に、簡潔であるほどより明快になる。しかしまた、簡潔さは正反対の効果をもたらす”なまくら道具”ともなりえる: 正確さの次には、いつも読み手のことを考えよう。
何よりも Scala でプログラムしよう。君が書いているのは Java ではないし、Haskell でも、Python でもない。Scala のプログラムは、いずれの言語で書かれたものとも異なっている。プログラミング言語を効果的に使うには、君の問題をその言語の用語で表現するべきだ。Java のプログラムを無理矢理 Scala で表現しても、ほとんどの場合オリジナルより劣ったものになるだろう。
これは Scala の入門ではない。本ガイドは Scala に慣れ親しんだ読者を前提としている。これから Scala を学びたい読者には以下のような教材がある:
本ガイドは生きたドキュメントなので、我々の最新の”ベストプラクティス”を反映するために変更されるかもしれない。しかし、中核となるアイデアが変わることはないだろう: 可読性を常に優先せよ; 汎用的なコードを書き、しかし明瞭さを損なわないこと; シンプルな言語機能を活用せよ。シンプルさは偉大な力をもたらし、また(特に型システムにおける)難解さを回避できる。とりわけ、常にトレードオフを意識しよう。洗練された言語は複雑な実装を要求し、複雑さは複雑さを生む。推論の複雑さ、意味論の複雑さ、機能間相互作用の複雑さ、そして君の協力者への理解の複雑さを。したがって、複雑さは洗練がもたらす税金であり、効用がコストを上回っていることを常に確認すべきだ。
では、楽しんでほしい。
コードの書式の細かい話は(それが実践的である限りは)重要ではない。当然だが、スタイルに本質的な良し悪しはないし、個人的な好みはほぼ人によって異なる。しかし、同じ整形ルールを一貫して適用すれば、ほとんどの場合で可読性が高まる。特定のスタイルに馴染んだ読み手は、さらに別のローカルな慣習を把握したり、言語の文法の隅を解読したりする必要がない。
これは、重複度の高い文法を持つ Scala においては特に重要だ。メソッド呼び出しは分かりやすい例だ: メソッドは “.” を付けても、ホワイトスペースで空けても呼び出せる。同様に、ゼロまたは一つ引数を取るメソッドでは、丸カッコを付けても良いし付けなくても良い、といった様に。さらに、メソッド呼び出しの様々なスタイルは、文法上の様々な曖昧さをさらけ出す! 注意深く選ばれた整形ルールを一貫して適用することで、人間と機械の両方にとっての多くの曖昧さを解決できるのは間違いない。
我々は、Scala style guide を順守すると共に以下のルールを追加した。
インデントは、スペース 2 つとする。100 カラムを超える行は避ける。メソッド、クラス、オブジェクトの定義同士の間に一行空ける。
i, j, k が期待される。Future.all ではなく Future.collect とした方がよい。
ok や err や defn は誰もが知っている。しかし sfri はそれほど一般的ではない。val を使おう。` でオーバーロードするのは避ける`type` ではなく typ とする。user.setActive() ではなく user.activate() とする。src.defined ではなく src.isDefined とする。get を付けないsite.getCount ではなく site.count とする。object User {
def getUser(id: Int): Option[User]
}object User {
def get(id: Int): Option[User]
}User.getUser は冗長だし、User.get よりも多くの情報を与えない。
import com.twitter.concurrent.{Broker, Offer}import com.twitter.concurrent._
scala.collection.immutable と scala.collection.mutable の一方あるいは両方をインポートして名前を修飾するimmutable.Map")import com.twitter
import concurrentimport com.twitter.concurrent中カッコは複合式を作るのに使われる(“モジュール言語”では他の用途にも使われる)。このとき、複合式の値はリスト中の最後の式だ。単純な式に中カッコを使うのはやめよう。
def square(x: Int) = x*x
と書く代わりに、メソッドの本体を構文的に見分けられるように
def square(x: Int) = {
x * x
}
と書きたくなるかもしれない。しかし、最初の方がゴチャゴチャしていなくて読みやすい。明確化が目的でないなら仰々しい構文を使うのはやめよう。
関数定義の中で、パターンマッチを直接使える場合はいつでもそうしよう。
list map { item =>
item match {
case Some(x) => x
case None => default
}
}
という間接的な書き方では意図がはっきりしない。代わりに match を折り畳んで
list map {
case Some(x) => x
case None => default
}
と書くと、リストの要素を写像 (map over) していることが分かりやすい。
ScalaDoc を使って API ドキュメントを提供しよう。以下のスタイルで書こう:
/**
* ServiceBuilder builds services
* ...
*/
しかし、標準の ScalaDoc スタイルは使わない方がいい:
/** ServiceBuilder builds services
* ...
*/
アスキーアートや視覚的な装飾に頼ってはいけない。また、API ではない不必要なコメントをドキュメント化すべきでない。もし、コードの挙動を説明するためにコメントを追加しているのに気づいたら、まずは、それが何をするコードなのか明白になるよう再構築できないか考えてみよう。”見るからに、それは動作する (it works, obviously)”よりも”明らかにそれは動作する (obviously it works)”方がいい(ホーアには申し訳ないけど[1])。
型システム (type system) の主な目的は、プログラミングの誤りを検出することだ。型システムは、制限された静的検査を効果的に提供する。これを使うと、コードについてある種の不変条件 (invariant) を記述して、それをコンパイラで検証できる。型システムがもたらす恩恵はもちろん他にもあるが、エラーチェックこそ、その存在理由(レーゾンデートル)だ。
我々が型システムを使う場合はこの目的を踏まえるべきだが、一方で、読み手にも気を配り続ける必要がある。型を慎重に使ったコードは明瞭さが高まるが、過剰に巧妙に使ったコードは読みにくいだけだ。
Scala の強力な型システムは、学術的な探求と演習においてよく題材とされる (例: Type level programming in Scala)。これらのテクニックは学術的に興味深いトピックだが、プロダクションコードでの応用において有用であることは稀だ。避けるべきだろう。
Scala では戻り型アノテーション (return type annotation) を省略できるが、一方でアノテーションは優れたドキュメンテーションを提供する。特に、public メソッドにとっては重要だ。戻り型が明白で露出していないメソッドの場合は省略しよう。
これは、ミックスインを使ったオブジェクトのインスタンス化において、Scala コンパイラがシングルトン型を生成する際に特に重要だ。例えば、make 関数が:
trait Service
def make() = new Service {
def getId = 123
}
Service という戻り型を持たない場合、コンパイラは細別型 (refinement type) の Object with Service{def getId: Int} を生成する。代わりに、明示的なアノテーションを使うと:
def make(): Service = new Service{}
make の公開する型を変更することなく、トレイトをさらに好きなだけミックスできる。つまり、後方互換性の管理が容易になる。
変位 (variance) は、ジェネリクスが派生型 (subtyping) と結びつく際に現れる。変位は、コンテナ型 (container type) の派生型と、要素型 (contained type) の派生型がどう関連するかを定義する。Scala では変位アノテーションを宣言できるので、コレクションに代表される共通ライブラリの作者は、多数のアノテーションを扱う必要がある。変位アノテーションは共有コードの使い勝手にとって重要だが、誤用すると危険なものになりうる。
非変 (invariant) は高度だが、Scala の型システムにとって必須の特徴であり、派生型の適用を助けるために広く(そして正しく)使われるべきだ。
不変コレクションは共変 (covariant) であるべきだ。要素型を受け取るメソッドは、コレクションを適切に“格下げ”すべきだ:
trait Collection[+T] {
def add[U >: T](other: U): Collection[U]
}
可変コレクションは非変であるべきだ。共変は、通常は可変コレクションにおいては無効だ。この
trait HashSet[+T] {
def add[U >: T](item: U)
}
と、以下の型階層について考えてみよう:
trait Mammal
trait Dog extends Mammal
trait Cat extends Mammal
もしここに犬 (Dog) のハッシュセットがあるなら、
val dogs: HashSet[Dog]
それを哺乳類 (Mammal) の集合として扱ったり、猫 (Cat) を追加したりできる。
val mammals: HashSet[Mammal] = dogs
mammals.add(new Cat{})
これはもはや、犬の HashSet ではない!
型エイリアス (type alias) を使うと、便利な名前を提供したり、意味を明瞭にしたりできる。しかし、一目瞭然な型をエイリアスすべきではない。
() => Int
は、短くて一般的な型を使っているので、
type IntMaker = () => Int
IntMaker
よりも意味が明瞭だ。しかし、
class ConcurrentPool[K, V] {
type Queue = ConcurrentLinkedQueue[V]
type Map = ConcurrentHashMap[K, Queue]
...
}
は、意思疎通が目的で簡潔さを高めたい場合に有用だ。
エイリアスが使える場合は、サブクラスにしてはいけない。
trait SocketFactory extends (SocketAddress => Socket)
SocketFactory は Socket を生成する関数だが、型エイリアス
type SocketFactory = SocketAddress => Socket
を使う方がいい。これで、SocketFactory 型の値となる関数リテラルが提供されるので、関数合成が使える:
val addrToInet: SocketAddress => Long
val inetToSocket: Long => Socket
val factory: SocketFactory = addrToInet andThen inetToSocket
パッケージオブジェクトを使うと、型エイリアスをトップレベル名として束縛できる:
package com.twitter
package object net {
type SocketFactory = (SocketAddress) => Socket
}
型エイリアスは新しい型ではないことに注意しよう。型エイリアスは、エイリアスされた名前をその型へと構文的に置換することと同等だ。
暗黙 (implicit) は強力な型システムの機能だが、慎重に使うべきだ。それらの解決ルールは複雑で、シンプルな字句検査においてさえ、実際に何が起きているか把握するのを困難にする。暗黙を間違いなく使ってもいいのは以下の状況だ:
Manifest(Scala 2.10 以降は TypeTag)のため暗黙を使おうとする時は、暗黙を使わずに同じことを達成する方法がないか常に確認しよう。
似通ったデータ型同士を、自動的に変換するために暗黙を使うのはやめよう(例えば、リストをストリームに変換する等)。明示的に変換するべきだ。それらの型はそれぞれ異なった動作をするので、読み手は暗黙の型変換が働いていないか注意しなくてはならなくなる。
Scala のコレクションライブラリは非常に総称的 (generic) で、機能が豊富で、強力で、組み立てやすい。コレクションは高水準であり、多数の操作を公開している。多くのコレクション操作と変換を簡潔かつ読みやすく表現できるが、そうした機能を不注意に適用すると、しばしば正反対の結果を招く。全ての Scala プログラマは collections design document を読むべきだ。このドキュメントは、Scala のコレクションライブラリに対する優れた洞察とモチベーションをもたらしてくれる。
常に、要求を最もシンプルに満たすコレクションを使おう。
Scala のコレクションライブラリは巨大だ。Traversable[T] を基底とする入り組んだ継承階層だけでなく、ほとんどのコレクションに immutable 版と mutable 版がある。どんなに複雑でも、以下の図は immutable と mutable の双方の階層にとって重要な区別を含んでいる。
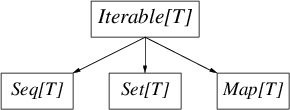
Iterable[T] はイテレート (iterate) できるコレクションで、iterator (と foreach) メソッドを提供する。Seq[T] は順序付けされたコレクション、Set[T] は数学的集合(要素が一意な順序付けのないコレクション)、そして Map[T] は順序付けのない連想配列だ。
不変 (immutable) コレクションを使おう。不変コレクションはほとんどの状況に適用できる。また、不変コレクションは参照透過なのでデフォルトでスレッドセーフとなり、プログラムの理解が容易になる。
明示的に mutable 名前空間を使おう。scala.collections.mutable._ を import して Set を参照するのではなく、
import scala.collections.mutable
val set = mutable.Set()
とすることで、可変版の `Set` が使われていることがはっきりする。
コレクション型のデフォルトコンストラクタを使おう。例えば、順序付きの(かつ連結リストである必要がない)シーケンスが必要な場合は、いつでも Seq() コンストラクタを使おう:
val seq = Seq(1, 2, 3)
val set = Set(1, 2, 3)
val map = Map(1 -> "one", 2 -> "two", 3 -> "three")
このスタイルでは、コレクションの動作とその実装が切り分けられるので、コレクションライブラリに対して最も適切な実装型を使わせることができる。君が必要なのは Map であって、必ずしも赤黒木ではない。さらに、これらのデフォルトコンストラクタは、しばしば特殊化された表現を用いる。例えば、Map() は 3 つのキーを持つマップに対して、フィールドを 3 つ持つオブジェクト(Map3 クラス)を使う。
以上の当然の帰結として、メソッドやコンストラクタでは、最も総称的なコレクション型を適切に受け取ろう。要するに、通常は上記の Iterable, Seq, Set、あるいは Map のうちのどれか一つだ。シーケンスが必要なメソッドには List[T] ではなく Seq[T] を使おう。
(注意: `scala.package` が定義するデフォルトの `Traversable`、`Iterable` と `Seq` は `scala.collection` バージョンだ。これに対して、`Predef.scala` が定義する `Map` と `Set` は `scala.collection.immutable` バージョンだ。これが意味するのは、例えば、デフォルトの `Seq` 型は不変と可変の*両方*になれるということだ。したがって、君のメソッドの引数が不変コレクションに依存するなら、 `Traversable`、`Iterable` や `Seq` を使う場合、明確に不変バージョンを require/import する必要がある。さもなければ、メソッドに可変バージョンが渡されるかもしれない。)
関数型プログラミングでは、パイプライン化した不変コレクションの変換によって、コレクションを望みの結果へと成形することが推奨されている。この手法により、多くの問題をとても簡潔に解決できるが、これは読み手を困惑させる可能性がある。パイプライン化した変換は時に作者の意図の理解を困難にするので、その場合、暗黙的に示される中間結果を全て追跡し続けるしかない。例えば、様々なプログラミング言語に対する投票である (language, num votes) のシーケンスを集計して、票数が最も多い言語から順番に表示するコードは以下のように書ける:
val votes = Seq(("scala", 1), ("java", 4), ("scala", 10), ("scala", 1), ("python", 10))
val orderedVotes = votes
.groupBy(_._1)
.map { case (which, counts) =>
(which, counts.foldLeft(0)(_ + _._2))
}.toSeq
.sortBy(_._2)
.reverse
このコードは簡潔でかつ正しい。しかし、ほとんどの読み手は作者の元々の意図を把握するのに苦労するだろう。中間結果とパラメータに名前を付ける戦略は、多くの場合で作者の意図を明確にするのに役立つ:
val votesByLang = votes groupBy { case (lang, _) => lang }
val sumByLang = votesByLang map { case (lang, counts) =>
val countsOnly = counts map { case (_, count) => count }
(lang, countsOnly.sum)
}
val orderedVotes = sumByLang.toSeq
.sortBy { case (_, count) => count }
.reverse
このコードでは、施される変換を中間値の名前として、操作されるデータ構造をパラメータ名として表している。これにより、以前と同じくらい簡潔であるだけでなく、よりいっそう明瞭な表現となっている。もし名前空間の汚染が心配なら、式を {} でグループ化すると良い:
val orderedVotes = {
val votesByLang = ...
...
}
高水準コレクションライブラリは(高水準な構築物が一般的にそうであるように)性能の推測が難しい。コンピュータに直接指示する”命令型スタイル”から遠ざかるほど、あるコード片が性能に与える影響を厳密に予測するのは困難になる。一方で、コードの正確さを判断するのは概して容易だし、読みやすさも高まる。Scala の場合、Java ランタイムが事態をさらに複雑にしている。Scala はユーザに対してボクシング (boxing) およびアンボクシング (unboxing) 操作を隠蔽するので、性能やメモリ使用量の面で重大なペナルティを被ることがある。
低レベルにおける細部に注目する前に、君の用途に対してコレクションの使い方が適切かどうか確認しよう。また、データ構造に予期しない漸近的な複雑さがないか確かめよう。Scala のさまざまなコレクションの複雑さについてはこちらで述べられている。
性能最適化の第一法則は、君のアプリケーションがなぜ遅いのかを理解することだ。最適化を始める前に、君のアプリケーションをプロファイル[2]してデータを取ろう。最初に注目するのは、回数の多いループや巨大なデータ構造だ。最適化への過度な取り組みは、たいてい無駄な努力に終わる。クヌースの”時期尚早な最適化は諸悪の根源”という格言を思い出そう。
性能やメモリ効率が要求される場面では、多くの場合で低レベルコレクションを使うのが妥当だ。巨大なシーケンスには、リストより配列を使おう(不変の Vector コレクションは、配列への参照透過なインタフェースを提供する)。また、性能が重要な場合は、シーケンスを直接生成せずにバッファを使おう。
Java コレクションと Scala コレクションと相互運用するには、scala.collection.JavaConverters を使おう。JavaConverters は、暗黙変換を行う asJava メソッドと asScala メソッドを追加する。読み手のために、これらの変換は明示的に行うようにしよう:
import scala.collection.JavaConverters._
val list: java.util.List[Int] = Seq(1,2,3,4).asJava
val buffer: scala.collection.mutable.Buffer[Int] = list.asScala
現代のサービスは高い並行性 (concurrency) を備え、サーバが何万何十万もの同時操作をコーディネートするのが一般的になっている。そして、堅固なシステムソフトウェアを記述する上で、暗黙的な複雑性への対処は中心的なテーマだ。
スレッド (thread) は、並行性を表現する手段の一つだ。スレッドを使うことで、オペレーティングシステムによってスケジュールされる、ヒープを共有する独立した実行コンテクストを利用できる。しかし、Java においてスレッド生成はコストが高いので、典型的にはスレッドプールを使うことで、スレッドをリソースとして管理する必要がある。これは、プログラマにとってさらなる複雑さと高い結合度を生み出す。つまり、アプリケーションロジックと、それが使用する潜在的なリソースを分離するのが難しくなる。
この複雑さは、出力 (fan-out) の大きいサービスを作成する際に、とりわけ明らかになる。それぞれの受信リクエストからは、システムのさらに別の階層に対する多数のリクエストが生じる。それらのシステムにおいて、スレッドプールは各階層でのリクエストの割合によってバランスを保つように管理される必要がある。あるスレッドプールで管理に失敗すると、その影響は他のスレッドプールにも広がってしまう。
また、堅固なシステムはタイムアウトとキャンセルについても検討する必要がある。どちらに対処するにも、さらなる”制御スレッド”を導入する必要があるので、問題がさらに複雑になる。ちなみに、もしスレッドのコストが安いなら問題は低減できる。スレッドプールが必要なくなり、タイムアウトしたスレッドを放棄することができ、追加のリソース管理も必要ないからだ。
このように、リソース管理はモジュール性を危うくするのだ。
Future で並行性を管理しよう。Future は、並行操作とリソース管理を疎結合にする。例えば、Finagle はわずかな数のスレッド上で並行操作を効率的に多重化する。Scala には軽量なクロージャリテラル構文があるので、Future のために新たな構文を覚える必要がなく、ほとんどのプログラマにとって自然に扱える。
Future は、プログラマが並行計算を宣言的なスタイルで表現できるようにする。Future は合成可能で、また計算の失敗を一定の原則に基づいて処理できる。こうした性質は Future は関数型プログラミング言語にとても適しており、推奨されるスタイルだと確信している。
生成した Future を変換しよう。Future の変換は、失敗の伝播やキャンセルの通知が行われることを保証し、またプログラマが Java メモリモデルの影響を検討する必要がなくなる。注意深いプログラマでさえ、RPC を逐次的に 10 回発行して結果を表示するプログラマを以下のように書いてしまうかもしれない:
val p = new Promise[List[Result]]
var results: List[Result] = Nil
def collect() {
doRpc() onSuccess { result =>
results = result :: results
if (results.length < 10)
collect()
else
p.setValue(results)
} onFailure { t =>
p.setException(t)
}
}
collect()
p onSuccess { results =>
printf("Got results %s\n", results.mkString(", "))
}
プログラマは、RPC の失敗が確実に伝播するように、コードに制御フローをいくつも挿入する必要がある。さらに悪いことに、このコードは間違っている! results を volatile として宣言していないので、繰り返しごとに results が一つ前の値を保持していることを保証できない。Javaのメモリモデルは、油断ならない獣だ。しかし幸いなことに、宣言的スタイルを使えばこれらの落とし穴を全て避けることができる:
def collect(results: List[Result] = Nil): Future[List[Result]] =
doRpc() flatMap { result =>
if (results.length < 9)
collect(result :: results)
else
Future.value(result :: results)
}
collect() onSuccess { results =>
printf("Got results %s\n", results.mkString(", "))
}
ここでは flatMap を使って操作を順序付けし、処理が進むにつれてリストの先頭に結果を追加している。これは、関数型プログラミングの一般的なイディオムを Future に置き換えたものだ。これは正しく動作するだけでなく、必要な”おまじない”が少なくなるし、エラーの温床が減り、そして読みやすい。
Future のコンビネータ (combinator) を使おう。Future.select, Future.join, Future.collect は、複数の Future を組み合わせて操作する際の一般的なパターンを体系化している。
並行コレクションの話題は、私見と、機微と、ドグマと、FUD に満ちている。それらは、大抵の実践的な状況においては取るに足らない問題だ: 目的を果たすためには、いつでも最も単純で、最も退屈で、最も標準的なコレクションから始めよう。同期化コレクションでは上手くいかないことが分かる前に、並行コレクションを手に取ってはいけない。JVM は、同期を低コストで実現する洗練された機構を持っている。その効率に君は驚くだろう。
不変 (immutable) コレクションで目的を果たせるなら、それを使おう。不変コレクションは参照透過なので、並行コンテキストでの推論が簡単になる。不変コレクションの変更は、主に(var セルや AtomicReference が指す)現在の値への参照を更新することで行う。不変コレクションの変更は注意が必要だ。他のスレッドへ不変コレクションを公開するには、AtomicReference は再試行が必要だし、var 変数は volatile として宣言しなければならない。
可変 (mutable) な並行コレクションは複雑な動作をするだけでなく、Java メモリモデルの微妙な部分を利用するので、特に更新を公開する方法などの暗黙的な挙動を理解しておこう。同期化コレクションの方が合成は簡単だ。並行コレクションでは getOrElseUpdate のような操作を正しく実装できないし、特に並行コレクションの合成はエラーの温床になる。
関数型スタイルのプログラムは、従来の制御構造が少なくなり、また、宣言型スタイルで書かれていると読みやすいことが多い。こうしたスタイルでは、典型的にはロジックをいくつかの小さなメソッドや関数に分解し、それらを互いに match 式で貼り合わせる。また、関数型プログラムは、より式指向となる傾向がある: つまり、条件式のそれぞれの分岐は同じ型の値を計算し、for (..) yield は内包 (comprehension) を計算する。また、再帰の利用が一般的だ。
再帰表現を使うと、問題をしばしば簡潔に記述できる。そしてコンパイラは、末尾呼び出しの最適化が適用できるコードを正規のループに置き換える(末尾最適化が適用されるかは @tailrec アノテーションで確認できる)。
ヒープの fix-down アルゴリズムの、極めて標準的な命令型バージョンを検討しよう:
def fixDown(heap: Array[T], m: Int, n: Int): Unit = {
var k: Int = m
while (n >= 2*k) {
var j = 2*k
if (j < n && heap(j) < heap(j + 1))
j += 1
if (heap(k) >= heap(j))
return
else {
swap(heap, k, j)
k = j
}
}
}
このコードでは、while ループに入るたびに一つ前の反復で変更された状態を参照する。各変数の値は、どの分岐を取るかに依存する。そして、正しい位置が見つかるとループの中盤で return する(鋭い読者は、ダイクストラの “Go To Statement Considered Harmful” [3] に同様の議論があることに気づくと思う)。
(末尾)再帰による実装を検討しよう[4]:
@tailrec
final def fixDown(heap: Array[T], i: Int, j: Int) {
if (j < i*2) return
val m = if (j == i*2 || heap(2*i) < heap(2*i+1)) 2*i else 2*i + 1
if (heap(m) < heap(i)) {
swap(heap, i, m)
fixDown(heap, m, j)
}
}
ここでは、すべての反復は明確に定義された白紙の状態から開始する。また、参照セルが存在しないので不変式 (invariant) を数多く見出せる。このメソッドはより推論しやすく、より読みやすい。さらに、性能面のペナルティもない。メソッドは末尾再帰なので、コンパイラがこれを標準的な命令型のループへと変換するからだ。
前節では再帰を使うメリットを紹介したが、とはいえ命令型の構造が無価値だというわけではない。多くの場合、計算を早期に終了する方が、終点の可能性がある全ての位置に条件分岐を持つよりも適切だ。実際に、上記の fixDown がヒープの終端に達すると return によって早期に終了する。
return を使うと、分岐を減らして不変式 (invariant) を定めることができる。これにより、入れ子が減ってコードを追いやすくなるだけでなく、後続のコードの正当性を推論しやすくなる(配列の範囲外をアクセスしないことを確認する場合とか)。これは、“ガード”節で特に有用だ:
def compare(a: AnyRef, b: AnyRef): Int = {
if (a eq b)
return 0
val d = System.identityHashCode(a) compare System.identityHashCode(b)
if (d != 0)
return d
// slow path..
}
return を使って、コードを明快にして読みやすさを高めよう。ただし、命令型言語でのような使い方をしてはいけない。つまり、計算結果を返すために return を使うのは避けよう。
def suffix(i: Int) = {
if (i == 1) return "st"
else if (i == 2) return "nd"
else if (i == 3) return "rd"
else return "th"
}
と書く代わりに下記のように書こう:
def suffix(i: Int) =
if (i == 1) "st"
else if (i == 2) "nd"
else if (i == 3) "rd"
else "th"
しかし、match 式を使うのがより優れた方法だ:
def suffix(i: Int) = i match {
case 1 => "st"
case 2 => "nd"
case 3 => "rd"
case _ => "th"
}
なお、クロージャの内部で return を使うと目に見えないコストが発生する場合があるので注意しよう。
seq foreach { elem =>
if (elem.isLast)
return
// process...
}
この `return` は、バイトコードでは例外を `throw` と `catch` するコードとして実装されるので、実行頻度の高いコード内で使うと性能に影響を与える。
forループと内包for を使うと、ループと集約を簡潔かつ自然に表現できる。for は、多数のシーケンスを平坦化 (flatten) する場合に特に有用だ。for の構文は、内部的にはクロージャを割り当ててディスパッチしていることを覆い隠している。これにより予期しないコストが発生したり、予想外の挙動を示したりする。例えば、
for (item <- container) {
if (item != 2) return
}
このコードは `container` が遅延評価されるとランタイムエラーが発生し、これにより return が非局所的 (nonlocal) に評価されてしまう!
これらの理由から、コードを明瞭にするためである場合を除いて、for の代わりに foreach, flatMap, map, filter を直接呼び出すのが良いことが多い。
(訳者による補足: Scala の for 式は `foreach`, `flatMap`, `map`, `withFilter` を呼び出す糖衣構文で、ループ内の式は、コンパイル時にそれらのメソッドに渡される匿名関数に変換される。例えば、上記の for 式は:
container foreach { item =>
if (item != 2) return
}
というコードとして実行される。本ガイドでは、最初からこのように記述することを推奨している。
ところで、ネストした匿名関数での return 式は、ランタイムエラーである NonLocalReturnException の throw と catch に変換される。この場合、for 式の中の container が遅延評価されると return 式の挙動が意図しないものになる場合がある。詳細に興味がある読者はこちらの議論も参照してほしい。)
require と assertrequire と assert は、どちらも実行可能なドキュメントとして機能する。これらは、型システムが要求される不変条件 (invariant) を表現できない状況で有用だ。assert は、コードが仮定する(内部あるいは外部の)不変条件を表現するために使われる。例えば、
val stream = getClass.getResourceAsStream("someclassdata")
assert(stream != null)
一方で、require は API の契約を表現するために使われる:
def fib(n: Int) = {
require(n > 0)
...
}
値指向プログラミングは、特に関数型プログラミングと一緒に用いることで数々の利益をもたらす。このスタイルはステートフルな変更よりも値の変換を重視し、参照透過 (referentially transparent) なコードを生み出し、より強力な不変式 (invariant) を提供するので、推論が容易になる。ケースクラス、パターンマッチ、構造化代入 (destructuring binding) 、型推論、クロージャやメソッドの軽量な生成構文がこの仕事の道具になる。
ケースクラス (case class) は、代数的データ型 (algebraic data type) をエンコードする: ケースクラスは数多くのデータ構造をモデリングするのに役に立ち、強力な不変式を簡潔なコードとして提供する。ケースクラスは、パターンマッチと共に利用すると特に有用だ。パターンマッチの解析器は、さらに強力な静的保証を提供する包括的解析 (exhaustivity analysis) を実装している。
ケースクラスで代数的データ型をエンコードする際は、以下のパターンを使おう:
sealed trait Tree[T]
case class Node[T](left: Tree[T], right: Tree[T]) extends Tree[T]
case class Leaf[T](value: T) extends Tree[T]
Tree[T] 型には Node と Leaf の 2 つのコンストラクタがある。型を sealed として宣言するとソースファイルの外でコンストラクタを追加できなくなるので、コンパイラに包括的解析を行わせることができる。
パターンマッチと共に使うと、上記のモデリングは簡潔でありかつ”明らかに正しい”コードになる:
def findMin[T <: Ordered[T]](tree: Tree[T]) = tree match {
case Node(left, right) => Seq(findMin(left), findMin(right)).min
case Leaf(value) => value
}
木構造のような再帰的構造は、代数的データ型の古典的な応用を占めるが、代数的データ型が有用な領域はそれよりずっと大きい。特に、状態機械によく現れる直和 (disjoint union) は、代数的データ型で容易にモデル化できる。
Option 型は、空の状態 (None) と満たされた状態 (Some(value)) のいずれかであるコンテナだ。Option は null の安全な代替手段を提供するので、いつでも可能な限り利用するべきだ。Option は(たかだか要素が一つの)コレクションなので、コレクション操作を利用できる。使うしかない!
以下のように書くのは安全ではない:
var username: String = null
...
username = "foobar"
以下のように書こう:
var username: Option[String] = None
...
username = Some("foobar")
Option 型は、username が空であるかのチェックを静的に強制してくれるのでより安全だ。
Option 値の条件実行は foreach を使うべきだ。以下のように書く代わりに:
if (opt.isDefined)
operate(opt.get)
以下のように書こう:
opt foreach { value =>
operate(value)
}
このスタイルは奇妙に思えるかもしれないが、より優れた安全性と簡潔さを提供する(例外を引き起こしうる get は呼んでいない)。空の場合と値を持つ場合の両方の分岐がありうるなら、パターンマッチを使おう:
opt match {
case Some(value) => operate(value)
case None => defaultAction()
}
しかし、もし値がない場合にデフォルト値で良いなら getOrElse がある。
operate(opt getOrElse defaultValue)
Option の濫用はよくない: もし、Null Object のような目的にあったデフォルト値があるなら、代わりにそれを使おう。
また Option は、null になり得る値をラップできる、扱いやすいコンストラクタと共に使おう:
Option(getClass.getResourceAsStream("foo"))
は Option[InputStream] だが、getResourceAsStream が null を返す場合に None を返す。
パターンマッチ (x match { ...) は、うまく書かれた Scala コードのあらゆる場所で使われる。パターンマッチは、条件実行と分解、そして一つの構成物へのキャストの 3 つを融合する。うまく使うことで明快さと安全性の双方を高められる。
型ごとに処理を切り替える実装にパターンマッチを使う:
obj match {
case str: String => ...
case addr: SocketAddress => ...
また、パターンマッチは分解と組み合わせることで最も良い働きを示す。ケースクラスにマッチする際は、以下のように書かずに:
animal match {
case dog: Dog => "dog (%s)".format(dog.breed)
case _ => animal.species
}
以下のように書く:
animal match {
case Dog(breed) => "dog (%s)".format(breed)
case other => other.species
}
カスタム抽出子を書くのはコンストラクタ (apply) が重複する場合のみとする。さもなければ不自然になる可能性がある。
デフォルト値にもっと意味がある場合は、条件実行にパターンマッチを使うべきではない。コレクションライブラリは、普通は Option を返すメソッドを提供している。以下のように書くのは避けるべきだ:
val x = list match {
case head :: _ => head
case Nil => default
}
なぜなら、
val x = list.headOption getOrElse default
の方がより短くて目的が伝わりやすいからだ。
Scala は、部分関数 (PartialFunction) を定義できる構文的な簡易記法を提供する:
val pf: PartialFunction[Int, String] = {
case i if i%2 == 0 => "even"
}
また、これらは orElse と組み合わせられる。
val tf: (Int => String) = pf orElse { case _ => "odd"}
tf(1) == "odd"
tf(2) == "even"
部分関数は多くの場面に現れるが,PartialFunction で効率的にエンコードできる。メソッドの引数として利用する例:
trait Publisher[T] {
def subscribe(f: PartialFunction[T, Unit])
}
val publisher: Publisher[Int] = ...
publisher.subscribe {
case i if isPrime(i) => println("found prime", i)
case i if i%2 == 0 => count += 2
/* ignore the rest */
}
また、Option を返す代わりに:
// Attempt to classify the the throwable for logging.
type Classifier = Throwable => Option[java.util.logging.Level]
PartialFunction で表現した方が良い場面もある:
type Classifier = PartialFunction[Throwable, java.util.Logging.Level]
なぜなら、PartialFunction の組み合わせ可能な性質を大いに活かせるからだ:
val classifier1: Classifier
val classifier2: Classifier
val classifier = classifier1 orElse classifier2 orElse { _ => java.util.Logging.Level.FINEST }
構造化代入 (destructuring binding[5]) は値の代入の一種であり、パターンマッチと関連している。構造化代入とパターンマッチは同じメカニズムを利用するが、例外の可能性を許容しないために、厳密に選択肢が一つだけのときにのみ適用できる。構造化代入は、特にタプルやケースクラスを使う際に有用だ。
val tuple = ('a', 1)
val (char, digit) = tuple
val tweet = Tweet("just tweeting", Time.now)
val Tweet(text, timestamp) = tweet
Scala において、lazy で修飾された val フィールド(遅延フィールド)は必要になったときに計算される。なぜなら、Scala ではフィールドとメソッドは等価だからだ(Scala のフィールドを Java のフィールドと同じものにしたい場合は private[this] を使う)。
lazy val field = computation()
は(おおよそ)以下のようなコードの簡易記法だ:
var _theField = None
def field = if (_theField.isDefined) _theField.get else {
_theField = Some(computation())
_theField.get
}
すなわち、計算して結果を記憶する。遅延フィールドは、この目的のために使うようにする。しかし、意味論によって遅延を要求される場合に遅延評価を使うべきではない。このような場合には明示的に書いた方がよい。なぜなら、それによりコストモデルが明確になり、副作用をより精密に制御できるからだ。
遅延フィールドはスレッドセーフだ。
メソッドの引数は、名前によって特定してもよい。その意味は、引数を値ではなく、繰り返し評価されうる計算に対して束縛するということだ。値渡しの文脈を期待している呼び出し側を驚かせないように、この機能は注意深く適用すべきだ。この機能の目的は、構文的に自然な DSL を構築することにある。特に、新しい制御構造を、あたかも最初から言語に備わっている機能であるかのように見せることができる。
名前呼び出し (call-by-name) は、そのような制御構造に渡されるのが、呼び出し側にとって思いもよらない計算の結果ではなく”ブロック”であることが明らかな場合にのみ使おう。同様に、名前呼び出しの引数は、最後の引数リストの最後の位置でのみ使うべきだ。引数が名前呼び出しであるメソッドの名前は、呼び出し側にそのことが分かるように命名しよう。
値を複数回計算させたくて、特にその計算が副作用を持つなら明示的な関数を使おう:
class SSLConnector(mkEngine: () => SSLEngine)
提供者の意図はシグネチャから明らかであり、呼び出し側を驚かせることがない。
flatMapflatMap は map と flatten を組み合わせたもので、その巧妙な力と素晴らしい実用性によって特別な注目を浴びるに値する。flatMap は、その仲間の map と同様に、Future や Option のような従来とは異なるコレクションにおいてもしばしば利用可能だ。その振る舞いはシグネチャから明らかだ。ある Container[A] について、
flatMap[B](f: A => Container[B]): Container[B]
flatMap はコレクションの要素に対し、各要素から新しいコレクションを作り出す関数 f を呼び出した後、その生成した(全ての)コレクションを平坦化 (flatten) した結果を返す。例えば、同じ文字を繰り返さないような 2 文字の文字列の順列を全て取得するには:
val chars = 'a' to 'z'
val perms = chars flatMap { a =>
chars flatMap { b =>
if (a != b) Seq("%c%c".format(a, b))
else Seq()
}
}
これは、上記のコードをより簡潔に記述できる糖衣構文である for 内包記法と(おおよそ)等価だ:
val perms = for {
a <- chars
b <- chars
if a != b
} yield "%c%c".format(a, b)
flatMap は Option を扱う際にしばしば有用だ。flatMap を使うと、Option の連鎖を畳み込んで一つにできる。
val host: Option[String] = ...
val port: Option[Int] = ...
val addr: Option[InetSocketAddress] =
host flatMap { h =>
port map { p =>
new InetSocketAddress(h, p)
}
}
これも for を使えばもっと簡潔に記述できる。
val addr: Option[InetSocketAddress] = for {
h <- host
p <- port
} yield new InetSocketAddress(h, p)
Future における flatMap の使い方は”Future”の章で議論する。
Scala の偉大さの大部分は、オブジェクトシステムによるものだ。Scala はすべての値がオブジェクトであるという意味で純粋な言語であり、プリミティブ型と複合型の間に違いはない。Scala にはミックスイン (mixin) の機能もある。ミックスインを使うと、もっと直交的かつ段階的にモジュールを組み合わせられるだけでなく、そこにコンパイル時の静的な型検査を柔軟に組み合わせて、その恩恵をすべて享受できる。
ミックスインシステムの背景にある動機は、従来の依存性注入 (dependency injection) を不要にすることだ。その”コンポーネントスタイル”のプログラミングの極致こそが Cake パターン(日本語訳)だ。
しかし、Scala 自身が、”古典的な”(コンストラクタへの)依存性注入を利用する際の面倒な構文を、ほとんど取り除いてくれることが分かったので、Twitter ではむしろ依存性注入を使うようにしている: それはより明快で、依存性はやはり(コンストラクタの)型によってエンコードされ、クラスを構築する構文はとりたてて難しくなく扱いやすい。それは退屈で単純だが、うまくいく。依存性注入はプログラムをモジュール化するために使おう。そして、特に継承より合成を使おう。これにより、よりモジュール化されてテストが容易なプログラムになる。継承が必要な状況に遭遇したら、こう考えてみよう: ”もし継承をサポートしない言語を使うとしたら、このプログラムをどのように構造化するだろう?”と。その答えには説得力があるかもしれない。
通常、依存性注入にはトレイトを使う。
trait TweetStream {
def subscribe(f: Tweet => Unit)
}
class HosebirdStream extends TweetStream ...
class FileStream extends TweetStream ...
class TweetCounter(stream: TweetStream) {
stream.subscribe { tweet => count += 1 }
}
一般的には、注入するのは他のオブジェクトを生成するオブジェクトであるファクトリ (factory) だ。この場合、特化したファクトリ型ではなくシンプルな関数を使うべきだ。(訳者による補足: つまり、戻り値を持つあらゆる関数はファクトリとみなせるということ)
class FilteredTweetCounter(mkStream: Filter => TweetStream) {
mkStream(PublicTweets).subscribe { tweet => publicCount += 1 }
mkStream(DMs).subscribe { tweet => dmCount += 1 }
}
依存性注入を使用するからといって、共通のインタフェースや、トレイト (trait) に実装された共通コードを同時に使ってはならないということは全くない。それどころか、一つの具象クラスが複数のインタフェース(トレイト)を実装するかもしれず、また共通コードを全てのクラスで横断的に再利用するかもしれないので、トレイトの使用は強く推奨される。
トレイトは短くして直交性を保とう: 分割できる機能を一つのトレイトの塊にしてはいけない。互いに組み合わさる関連するアイデアのうち最小のものを考えるようにする。例えば、IO を行う何かがあるとしよう:
trait IOer {
def write(bytes: Array[Byte])
def read(n: Int): Array[Byte]
}
これを二つの振る舞いに分離する:
trait Reader {
def read(n: Int): Array[Byte]
}
trait Writer {
def write(bytes: Array[Byte])
}
そして、これらを互いに new Reader with Writer… のようにミックスインして、先ほどの IOer を形成する。インターフェイスの最小化は、よりよい直交性とモジュール化をもたらす。
Scala は、可視性を制御するための非常に表現力の高い修飾子を持つ。これらの修飾子は、何を公開 API として構成するかを定義するのに使うので重要だ。公開する API は限定されるべきだ。それによってユーザが実装の詳細にうっかり依存することがなくなり、また、作者が API を変更する能力を制限する。これらは、良いモジュール性にとって極めて重要だ。原則的に、公開 API を拡張するのは縮小するよりもはるかに簡単だ。また、アノテーションが貧弱だと、コードのバイナリの後方互換性が危うくなる。
private[this]private に指定したクラスメンバは、
private val x: Int = ...
そのクラス(サブクラスは除く)の全てのインスタンスから可視になる。ほとんどの場合、private[this] としたいだろう。
private[this] val x: Int = ...
これで x の可視性は特定のインスタンスに制限される。Scala コンパイラは、private[this] を単純なフィールドへのアクセスに変換できる(メンバへのアクセスが、静的に定義されたクラスに限定されるため)。これは時に、性能の最適化に寄与する。
Scala において、シングルトンクラス型を生成するのは一般的だ。例えば、
def foo() = new Foo with Bar with Baz {
...
}
このような状況で可視性を制限するには、戻り型を宣言する:
def foo(): Foo with Bar = new Foo with Bar with Baz {
...
}
foo() の呼び出し側は、返されたインスタンスの限定されたビュー (Foo with Bar) を見ることになる。
通常、構造的部分型 (structural type[6]) を使うべきではない。構造的部分型は便利で強力な機能だが、残念なことに JVM 上では効率的に実装されない。しかし、実装上の気まぐれによって、構造的部分型はリフレクションのためのとても優れた簡易記法を提供する。
val obj: AnyRef
obj.asInstanceOf[{def close()}].close()
Scala は例外機能を提供するが、正確さのためにプログラマが適切に対処すべき場合に、これを一般的なエラーに対して使ってはいけない。代わりに Option や com.twitter.util.Try を使うのは、慣習的で良い選択だ。これらは、型システムを利用して、ユーザがエラー処理を適切に考慮するようにする。
例えば、レポジトリを設計する時に、以下のような API にしたくなるかもしれない:
trait Repository[Key, Value] {
def get(key: Key): Value
}
しかし、これを実装すると key が存在しない時に例外を投げる必要がある。より良いやり方は Option を使うことだ:
trait Repository[Key, Value] {
def get(key: Key): Option[Value]
}
このインタフェースなら、レポジトリがあらゆる key を含まなくてもよく、またプログラマが key が見つからない場合に対処しなければならないことが明確になる。さらに、Option はこうしたケースに対処するための数多くのコンビネータを備えている。例えば、getOrElse は key が見つからない場合にデフォルト値を供給するのに使われる:
val repo: Repository[Int, String]
repo.get(123) getOrElse "defaultString"
Scala の例外機構は非チェック例外、つまりプログラマが可能性のある例外をカバーしているかをコンパイラが静的にチェックできないので、例外処理において広い網をかけたくなりがちだ。
しかし、いくつかの fatal(致命的)な例外は捕捉 (catch) するべきではない。
However, some exceptions are fatal and should never be caught; the code
try {
operation()
} catch {
case _ => ...
}
このコードは伝搬するべき致命的なエラーを捕捉してしまうので、ほとんどの場合で誤りだ。代わりに、非致命的な例外のみを捕捉する com.twitter.util.NonFatal 抽出子を使う。
try {
operation()
} catch {
case NonFatal(exc) => ...
}
Twitter では、実運用において多くの時間をガベージコレクションのチューニングに費している。ガベージコレクションにおける関心事は Java のそれとほとんど同じだが、関数型スタイルの副作用として、慣習的な Scala コードは Java よりも多くの(生存期間の短い)ガベージを生成する。HotSpot の世代別ガベージコレクションは、生存期間の短いガベージを効率的に解放するので、ほとんどの状況ではこれは問題にならない。
GC の性能問題に取り組む前に、Twitter でのいくつかの GC チューニングの経験について解説した Attila のプレゼンテーションを見て欲しい。
GC 問題を軽減するための Scala に特有な唯一の手段は、ガベージの生成をより少なくすることだ。しかし、データ無しで行動してはならない! 明らかに性能を劣化させる何かをしているのでなければ、Java の様々なプロファイリングツールを使おう。Twitter 自身も heapster や gcprof といったツールを提供している。
Twitter では、Java から使われるコードを Scala で書くとき、Java での慣習的な使い方ができるようにしている。多くの場合、追加の努力は必要ない。クラスと純粋な(実装を含まない)トレイトは、Java において対応するものと正確に同じものになる。しかし、時々、別個の Java API を提供する必要がある。ライブラリの Java API の感じをつかむ良い方法は、Java で単体テストを書くことだ(コンパイルが通れば良い)。このテストによってライブラリの Java ビューが安定していることが保証されるので、将来、Scala コンパイラが生成する実装が変化しても検出できる。
実装を含むトレイトは直接 Java から利用できない。代わりに、抽象クラスをトレイトと共に拡張する。
// 直接 Java からは利用できない
trait Animal {
def eat(other: Animal)
def eatMany(animals: Seq[Animal) = animals foreach(eat(_))
}
// しかし、これなら利用できる
abstract class JavaAnimal extends Animal
Twitter において、最も重要な標準ライブラリは Util と Finagle だ。Util は、Scala や Java の標準ライブラリの拡張という位置付けで、それらに欠けている機能やより適切な実装を提供する。Finagle は、Twitter の RPC システムで、分散システムの構成要素の中核だ。
Future については、並行性の章でも簡単に議論した。Future は非同期処理の協調において中心的な機構で、Twitter のコードベースや Finagle のコアで広く使われている。Future は並行イベントの合成を可能にするとともに、並行性の高い操作についての推論を単純化する。また Future を使うと、JVM 上で並行操作を非常に効率的に実装できる。
Twitter の Future は非同期だ。だから、例えばネットワーク入出力やディスク入出力のように、スレッドの実行を一時停止させうるブロッキング操作はシステムが処理する必要がある。このとき、システムはブロッキング操作の結果に対する Future を提供する。Finagle は、ネットワーク入出力のためのそうしたシステムを提供する。
Future は単純明瞭だ: Future は、まだ完了していない計算の結果を約束 (promise) する。Future は単純なコンテナ(プレースホルダ)だ。もちろん、計算は失敗することがあるので、この失敗もエンコードする必要がある。Future は、保留中 (pending)、失敗 (failed)、完了 (completed) の三つの状態のうち、ただ一つを取ることができる。
もう一度確認すると、合成 (composition) とは、単純なコンポーネントを結合してより複雑なコンポーネントにすることだ。関数合成は、合成の標準的な例だ: 関数 f と g が与えられたとき、合成関数 (g∘f)(x) = g(f(x)) は、まず x を f に適用して、その結果を g に適用した結果だ。この合成関数を Scala で書くと:
val f = (i: Int) => i.toString
val g = (s: String) => s+s+s
val h = g compose f // : Int => String
scala> h(123)
res0: java.lang.String = 123123123この関数 h は合成関数で、f と g の双方を所定の方法で結合した新しい関数だ。
Future はコレクションの一種だ。つまり、ゼロ個または一個の要素を持つコンテナであり、map や filter や foreach のような標準コレクションメソッドを持つ。Future の値は遅延されるので、これらのメソッドを適用した結果もまた必然的に遅延される。
val result: Future[Int]
val resultStr: Future[String] = result map { i => i.toString }
関数 { i => i.toString } は、整数値 i が利用可能になるまで呼び出されない。また、変換されたコレクション resultStr もその時まで保留状態になる。
リストは平坦化 (flatten) できる;
val listOfList: List[List[Int]] = ...
val list: List[Int] = listOfList.flatten
同様に、Future においても平坦化は意味をなす:
val futureOfFuture: Future[Future[Int]] = ...
val future: Future[Int] = futureOfFuture.flatten
Future は遅延するので、flatten の実装は(直ちに)Future を返す必要がある。この Future は、外側の Future(Future[Future[Int]]) が完了して、そのあとに内側の Future(Future[Future[Int]]) が完了するのを待っている結果だ。もし外側の Future が失敗したら、平坦化された Future も失敗する必要がある。
Future は、List と同様に flatMap を定義している。Future[A] が定義するシグネチャは、
flatMap[B](f: A => Future[B]): Future[B]
これは map と flatten の組み合わせたようなもので、そのように実装すると以下のようになる:
def flatMap[B](f: A => Future[B]): Future[B] = {
val mapped: Future[Future[B]] = this map f
val flattened: Future[B] = mapped.flatten
flattened
}
これは強力な組み合わせだ! flatMap を使うと、二つの Future を順番に実行した結果である Future を定義できる。これは、一つ目の Future の結果に基づいて計算される二つ目の Future だ。ユーザ (ID) の認証のために、二つの RPC を行う必要があると想像しよう。合成された操作は以下の方法で定義できる:
def getUser(id: Int): Future[User]
def authenticate(user: User): Future[Boolean]
def isIdAuthed(id: Int): Future[Boolean] =
getUser(id) flatMap { user => authenticate(user) }
こうした種類の結合のもう一つの恩恵は、エラー処理が組み込みになっていることだ: getUser(..) か authenticate(..) がさらにエラー処理をしない限り、isIdAuthed(..) が返す Future は失敗する。
Future のコールバックメソッド (respond, onSuccess, onFailure, ensure) は、その親に連鎖する新たな Future を返す。この Future は、親が完了した後でのみ完了することが保証されている。このパターンを実現するには、
acquireResource()
future onSuccess { value =>
computeSomething(value)
} ensure {
freeResource()
}
このとき freeResource() は computeSomething の後でのみ実行されることが保証される。これにより、ネイティブな try .. finally パターンのエミュレートを可能にする。
foreach の代わりに onSuccess を使おう。onSuccess の方が、onFailure と対称的で目的をより良く表す名前だし、連鎖も可能だ。
Promise インスタンスを直接作るのはいつでも避けるようにしよう: ほとんどのあらゆるタスクは、定義済みのコンビネータを使うことで達成できる。これらのコンビネータは、エラーやキャンセルの伝播を保証する。また、コンビネータは一般的にデータフロー・スタイルのプログラミングを促進し、これにより普段は同期化や volatile 宣言が不要になる。
末尾再帰方式で書かれたコードはスタック空間のリークを引き起こさないので、データフロー・スタイルでループを効率的に実装できる:
case class Node(parent: Option[Node], ...)
def getNode(id: Int): Future[Node] = ...
def getHierarchy(id: Int, nodes: List[Node] = Nil): Future[Node] =
getNode(id) flatMap {
case n@Node(Some(parent), ..) => getHierarchy(parent, n :: nodes)
case n => Future.value((n :: nodes).reverse)
}
Future は有用なメソッドをたくさん定義している。Future.value() や Future.exception() を使うと、事前に結果が満たされた Future を作れる。Future.collect(), Future.join(), Future.select() は、複数の Future を一つにまとめるコンビネータを提供する(つまり scatter-gather 操作の gather 部分)。
Future は弱いキャンセルを実装している。Future#cancel の呼び出しは、直ちに計算を終了させる代わりに、どれが最終的に Future を満たしたプロセスがなのか問い合わせることができるシグナルをレベルトリガで伝播する。キャンセルは、値とは反対方向へ伝播する: コンシューマ (consumer) がセットしたキャンセル・シグナルはプロデューサ (producer) へと伝播する。プロデューサは Promise の onCancellation を使って、シグナルに応じて作動するリスナーを指定する。
つまり、キャンセルの動作はプロデューサに依存するし、デフォルトの実装は存在しない。キャンセルはヒントに過ぎない。
Util ライブラリの Local は、特定の Future のディスパッチツリーに対するローカルな参照セルを提供する。Local に値をセットすると、同じスレッド内の Future によって遅延されるあらゆる計算がこの値を利用できるようになる。これらはスレッドローカルに似ているが、そのスコープが Java スレッドでなく”Future スレッド”のツリーである点が異なる。
trait User {
def name: String
def incrCost(points: Int)
}
val user = new Local[User]
...
user() = currentUser
rpc() ensure {
user().incrCost(10)
}
ここで ensure ブロック内の user() は、コールバックが追加された時点でのローカルな user の値を参照する。
スレッドローカルと同様に Local は非常に便利なこともあるが、ほとんどの場合は避けるべきだ: たとえそうした方が負担が少ないときでも、データを明示的に渡して回る方法では問題を十分に解決できないことを確認しよう。
Local は、コアライブラリにおける非常に一般的な関心事のために効果的に使われる: 例えば、RPC のトレースを使ったスレッド管理、モニタの伝播、Future コールバックのための”スタックトレース”の作成など、その他の解決策ではユーザに過度な負担がある場合だ。その他のほとんどの状況で Local は不適切だ。
並行システムは非常に複雑だ。それは、共有データやリソースへのアクセスを協調させる必要があるからだ。アクター (Actor) は、並行システムを単純にする一つの戦略を提起している。アクターは逐次的なプロセスで、それぞれのアクターが自分自身の状態やリソースを保持し、メッセージングによって他のアクターとデータを共有する。共有データはアクター間で通信する必要がある。
Offer と Broker は、これに基づいて三つの重要な考え方を取り入れている。一つ目は、通信チャネル (Broker) が第一級 (first class) であること。すなわち、アクターに直接メッセージを送るのではなく Broker 経由で送信する。二つ目は、Offer や Broker が同期化メカニズムであること: 通信することは同期化することだ。この意味は、Broker は協調メカニズムとして使えるということだ: プロセス a がプロセス b にメッセージを送信したとき、a と b は共にシステムの状態について合意する。三つ目は、通信が選択的に実行できること: 一つのプロセスはいくつか異なる通信を提案でき、それらのうちただ一つが有効になる。
一般的な(他の合成と同様の)やり方で選択的な通信をサポートするには、通信の行為 (act of communicating) から通信の記述 (description of a communication) を分離する必要がある。これをやるのが Offer だ。Offer は通信を記述する永続的な値で、(Offer に作用する)通信を実行するには Offer の sync() メソッドで同期化する。
trait Offer[T] {
def sync(): Future[T]
}
`sync()` は、通信が値を得たときに、交換された値を生成する Future[T] を返す。
Broker は通信のチャネルであり、Offer を使って値の交換を協調する:
trait Broker[T] {
def send(msg: T): Offer[Unit]
val recv: Offer[T]
}
そして、二つの Offer を生成するとき、
val b: Broker[Int]
val sendOf = b.send(1)
val recvOf = b.recv
sendOf と recvOf はどちらも同期化されており、
// In process 1:
sendOf.sync()
// In process 2:
recvOf.sync()
両方の Offer が値を得て 1 の値が交換される。
選択的な通信は、Offer.choose でいくつかの Offer を結合することで行われる。
def choose[T](ofs: Offer[T]*): Offer[T]
は新しい Offer を生成する。これは、同期化すると、ofs のうち最初に利用可能になったものを唯一つ取得する。いくつかが即座に利用可能になった場合は、取得する `Offer` はランダムに選ばれる。
Offer オブジェクトは、Broker から得た Offer と組み合わせて使うワンオフの Offer をたくさん持っている。
Offer.timeout(duration): Offer[Unit]
は与えられた期間の後に起動する Offer だ。Offer.never は決して値を取得しない。一方、Offer.const(value) は、与えられた値を直ちに取得する。これらは、選択的な通信によって合成するのにも有用だ。例えば、送信操作にタイムアウトを適用するには:
Offer.choose(
Offer.timeout(10.seconds),
broker.send("my value")
).sync()
Offer と Broker を使う方法と SynchronousQueue を比べてみたくなるが、両者には微妙だが重要な違いがある。Offer は、そうしたキューではとてもできないような方法で組み立てることができる。例えば、Broker で表した一連のキューを考える:
val q0 = new Broker[Int]
val q1 = new Broker[Int]
val q2 = new Broker[Int]
ここで、読み込みのためのマージされたキューを作ってみる:
val anyq: Offer[Int] = Offer.choose(q0.recv, q1.recv, q2.recv)
anyq は Offer で、最初に利用可能になったキューから読み込む。なお、この anyq はやはり同期的であり、内部にあるキューの動作を利用できる。こうした合成は、キューを使う方法ではとても不可能だ。
コネクションプールは、ネットワークアプリケーションでは一般的で、たいていは実装しにくい。例えば、個々のクライアントは異なるレイテンシを要求するため、プールからの取得にタイムアウトがあるのが多くの場合で望ましい。プールは原理的には単純だ: コネクションのキューを保持し、待機クライアント (waiter) が入ってきたら満たしてやる。従来の同期化プリミティブでは、典型的には二つのキューを使う。一つは waiters で、コネクション (connection) がない時に使われる。もう一つは connections で、これは待機クライアント (waiter) がない時に使われる。
Offer と Broker を使うと、これをとても自然に表現できる:
class Pool(conns: Seq[Conn]) {
private[this] val waiters = new Broker[Conn]
private[this] val returnConn = new Broker[Conn]
val get: Offer[Conn] = waiters.recv
def put(c: Conn) { returnConn ! c }
private[this] def loop(connq: Queue[Conn]) {
Offer.choose(
if (connq.isEmpty) Offer.never else {
val (head, rest) = connq.dequeue
waiters.send(head) { _ => loop(rest) }
},
returnConn.recv { c => loop(connq enqueue c) }
).sync()
}
loop(Queue.empty ++ conns)
}
loop は、コネクションが返却された状態にすることを常にオファー (offer) すると共に、キューが空でない場合のみ送信をオファーする。永続的なキューを使うことで推論をより単純にできる。プールのインタフェースにも Offer を使っているので、呼び出し側はコンビネータを使うことでタイムアウトを適用できる:
val conn: Future[Option[Conn]] = Offer.choose(
pool.get { conn => Some(conn) },
Offer.timeout(1.second) { _ => None }
).sync()
タイムアウトを実装するのにこれ以上の簿記は必要ない。これは Offer の動作によるものだ: もし Offer.timeout が選択されたら、もはやプールからの受信をオファーしない。つまり、プールと呼び出し側が waiters Broker 上での送信と受信をそれぞれ同時に合意することはない。
並行プログラムを、同期的に通信する一連の逐次的なプロセスとして構築するのは多くの場合で有用だし、場合によってはプログラムを非常に単純化できる。Offer と Broker は、これを単純化し統一化する手段を提供する。実際、それらのアプリケーションは、人によっては”古典的な”並行性の問題として考えるかもしれないものを乗り越える。サブルーチンやクラス、モジュールと同じように、(Offer や Broker を用いた)並行プログラミングは有用な構造化ツールだ。これは、制約充足問題 (Constraint Satisfaction Problem; CSP) からのもう一つの重要なアイデアだ。
これの一つの例はエラトステネスの篩で、整数ストリームに対するフィルタの連続的な適用として構造化できる。まず、整数の生成源が必要だ:
def integers(from: Int): Offer[Int] = {
val b = new Broker[Int]
def gen(n: Int): Unit = b.send(n).sync() ensure gen(n + 1)
gen(from)
b.recv
}
integers(n) は、単に n から始まる全ての連続した整数の Offer だ。次に、フィルタが必要だ:
def filter(in: Offer[Int], prime: Int): Offer[Int] = {
val b = new Broker[Int]
def loop() {
in.sync() onSuccess { i =>
if (i % prime != 0)
b.send(i).sync() ensure loop()
else
loop()
}
}
loop()
b.recv
}
filter(in, p) は、in から素数 p の倍数を取り除く Offer を返す。最後に、篩 (sieve) を定義する:
def sieve = {
val b = new Broker[Int]
def loop(of: Offer[Int]) {
for (prime <- of.sync(); _ <- b.send(prime).sync())
loop(filter(of, prime))
}
loop(integers(2))
b.recv
}
loop() の動作は単純だ: of から次の素数を読み取り、この素数を除いた of にフィルタを適用する。loop が再帰するにつれて連続した素数がフィルタされ、篩が手に入る。これで、最初の 10000 個の素数を出力できる:
val primes = sieve
0 until 10000 foreach { _ =>
println(primes.sync()())
}
このアプローチは、篩を単純かつ直交するコンポーネントへと構造化できるだけでなく、ストリームとして扱える: 君は、興味がある素数の集合を事前に計算する必要がなく、いっそうモジュラリティを拡張できる。
本レッスンは、Twitter 社の Scala コミュニティによるものだ。私は誠実な記録者でありたい。
Blake Matheny と Nick Kallen、Steve Gury、そして Raghavendra Prabhu には、とても有益な助言と多くの優れた提案を与えてもらった。
本ドキュメントの日本語訳は、@okapies と @scova0731 が担当しました。
翻訳にあたっては、日本の Scala コミュニティから数多くの貢献を頂きました: @xuwei-k さん、@kmizu さん、@eed3si9n さん、@akr4 さん、@yosuke-furukawa さん、m hanada さん、および日本 Scala ユーザーズグループの皆さん。(以上、順不同)
また、@kmizu さんと@eed3si9n さんには、高度に専門的な議論について貴重な助言を頂きました。
ありがとうございます。